I work under one cluster in DataBricks which has mounted blob container. I'd like to keep that one container for the whole cluster, but mount another already created cluster for one specific notebook (or repo, that would be awesome) to load data from there. How can I make it?
Example:
Repo 1 - blob 1:
- notebooks blob 1 Repo 2 - blob 1 (or blob if its possible)
- notebook (notebooks) blob2
CodePudding user response:
You can use the following procedure load the data into storage account.
I reproduce same in my environment with two repro's
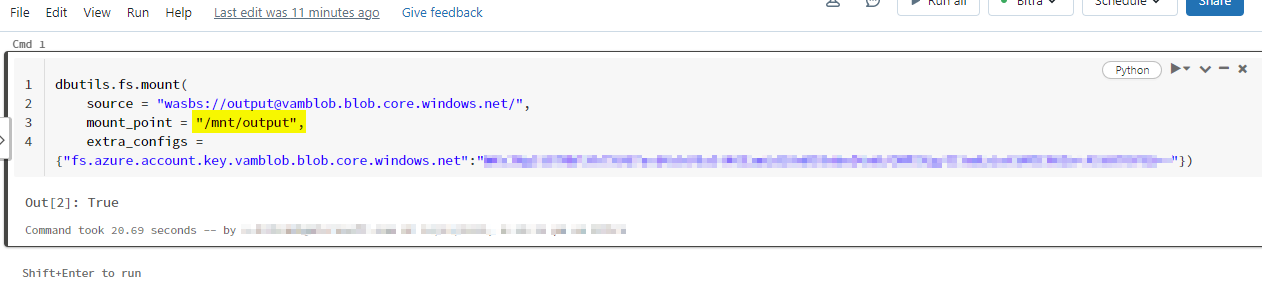
Repro 1:
Container name: input Mount_point:/mnt/hffj
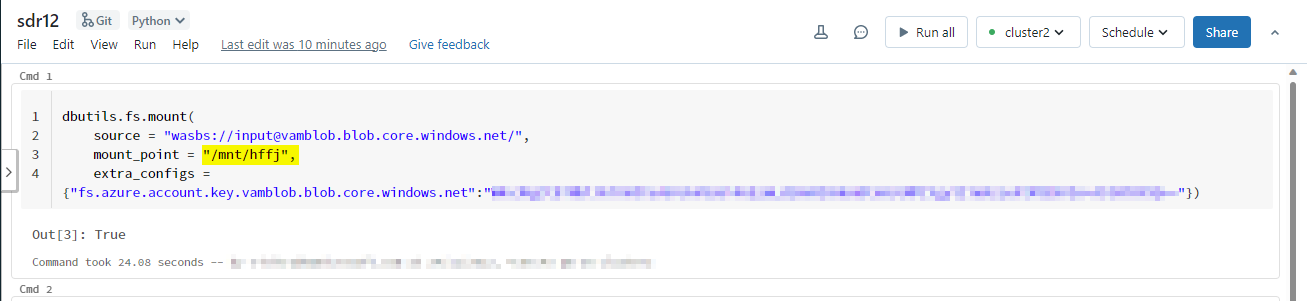
Repro 2:
Container name: output Mount_point:/mnt/output
As per above scenario you can do in this way:
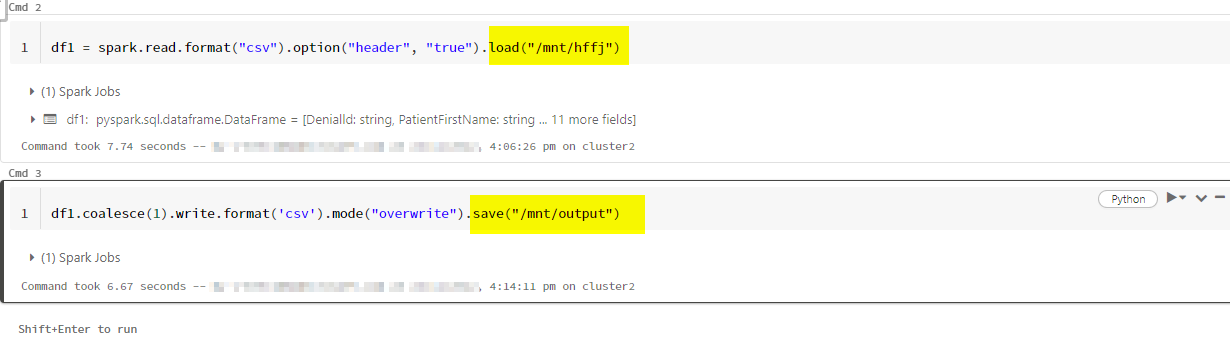
First of all read the data frame
df1 = spark.read.format("csv").option("header", "true").load("/mnt/hffj")
Then, write it into repro 2 mount path /mnt/output. Data is stored in that mount location
df1.coalesce(1).write.format('csv').mode("overwrite").save("/mnt/output")