Hi I have a usecase where I am reading parquet files and writing it to ADLG Gen 2. This is without any modification to data.
MY Code:
val kustoLogsSourcePath: String = "/mnt/SOME_FOLDER/2023/01/11/fe73f221-b771-49c9-ba7d-2e2af4fe4f2a_1_69fc119b888447efa9ed2ecd7a4ab647.parquet"
val outputPath: String = "/mnt/SOME_FOLDER/2023/01/10/EventLogs1/"
val kustoLogData = spark.read.parquet(kustoLogsSourcePath)
kustoLogData.write.mode(SaveMode.Overwrite).save(outputPath)
I am getting this error, any ideas how to solve it: Here, I have shared all the exception related messages that I got.
org.apache.spark.SparkException: Job aborted. at org.apache.spark.sql.execution.datasources.FileFormatWriter$.write(FileFormatWriter.scala:196) at org.apache.spark.sql.execution.datasources.InsertIntoHadoopFsRelationCommand.run(InsertIntoHadoopFsRelationCommand.scala:192) at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult$lzycompute(commands.scala:110) at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult(commands.scala:108) at org.apache.spark.sql.execution.command.DataWritingCommandExec.doExecute(commands.scala:128) at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:143) at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:131) at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$5.apply(SparkPlan.scala:183) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151) at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:180) at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:131) at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:114) at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:114) at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:690) at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:690) at
Caused by: org.apache.spark.SparkException: Job aborted due to stage failure: Task 276 in stage 2.0 failed 4 times, most recent failure: Lost task 276.3 in stage 2.0 (TID 351, 10.139.64.13, executor 5): com.databricks.sql.io.FileReadException: Error while reading file dbfs:[REDACTED]/eventlogs/2023/01/10/[REDACTED-FILE-NAME].parquet. at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1$$anon$2.logFileNameAndThrow(FileScanRDD.scala:272) at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1$$anon$2.getNext(FileScanRDD.scala:256) at org.apache.spark.util.NextIterator.hasNext(NextIterator.scala:73) at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.hasNext(FileScanRDD.scala:197) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage2.scan_nextBatch_0$(Unknown Source) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage2.processNext(Unknown Source) at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
Caused by: java.lang.UnsupportedOperationException: Unsupported encoding: DELTA_BYTE_ARRAY at org.apache.spark.sql.execution.datasources.parquet.VectorizedColumnReader.initDataReader(VectorizedColumnReader.java:584) at org.apache.spark.sql.execution.datasources.parquet.VectorizedColumnReader.readPageV2(VectorizedColumnReader.java:634) at org.apache.spark.sql.execution.datasources.parquet.VectorizedColumnReader.access$100(VectorizedColumnReader.java:49) at org.apache.spark.sql.execution.datasources.parquet.VectorizedColumnReader$1.visit(VectorizedColumnReader.java:557) at
Caused by: com.databricks.sql.io.FileReadException: Error while reading file dbfs:[REDACTED]/eventlogs/2023/01/11/fe73f221-b771-49c9-ba7d-2e2af4fe4f2a_1_69fc119b888447efa9ed2ecd7a4ab647.parquet. at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1$$anon$2.logFileNameAndThrow(FileScanRDD.scala:272) at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1$$anon$2.getNext(FileScanRDD.scala:256) at org.apache.spark.util.NextIterator.hasNext(NextIterator.scala:73) at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.hasNext(FileScanRDD.scala:197) at
Caused by: java.lang.UnsupportedOperationException: Unsupported encoding: DELTA_BYTE_ARRAY at org.apache.spark.sql.execution.datasources.parquet.VectorizedColumnReader.initDataReader(VectorizedColumnReader.java:584) at org.apache.spark.sql.execution.datasources.parquet.VectorizedColumnReader.readPageV2(VectorizedColumnReader.java:634) at
CodePudding user response:
It seems that some columns are DELTA_BYTE_ARRAY encoded, a workarround would be to turn off the vectorized reader property:
spark.conf.set("spark.sql.parquet.enableVectorizedReader", "false")
CodePudding user response:
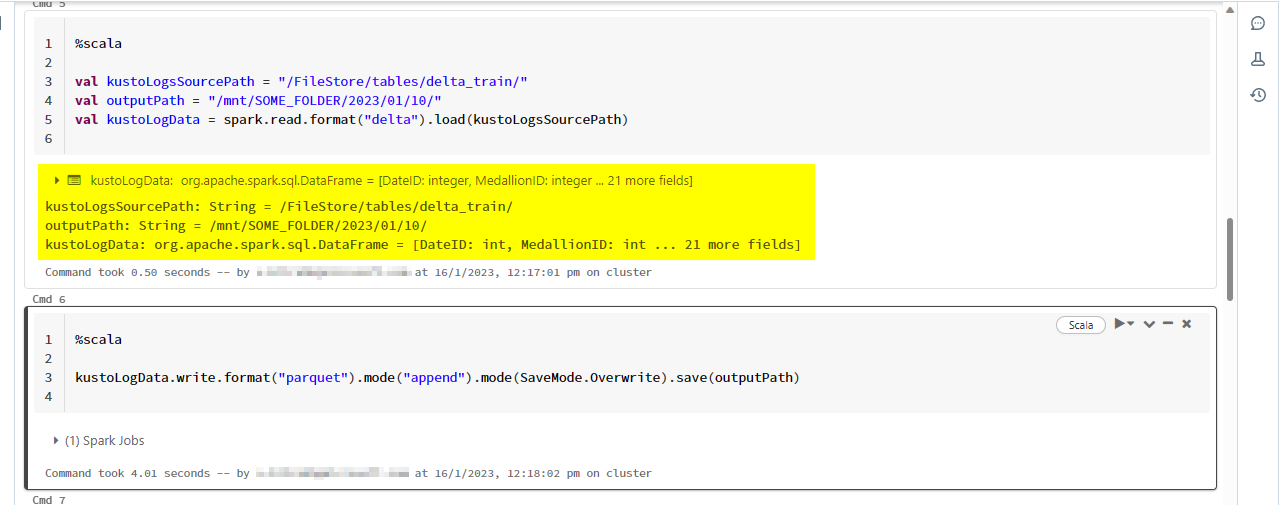
Try to modify your code and also remove the string parameter in the font of the variable and also use .format("delta") for reading delta file.
%scala
val kustoLogsSourcePath = "/mnt/SOME_FOLDER/2023/01/11/"
val outputPath = "/mnt/SOME_FOLDER/2023/01/10/EventLogs1/"
val kustoLogData = spark.read.format("delta").load(kustoLogsSourcePath)
kustoLogData.write.format("parquet").mode("append").mode(SaveMode.Overwrite).save(outputPath)
For the demo, this is my FileStore location /FileStore/tables/delta_train/.
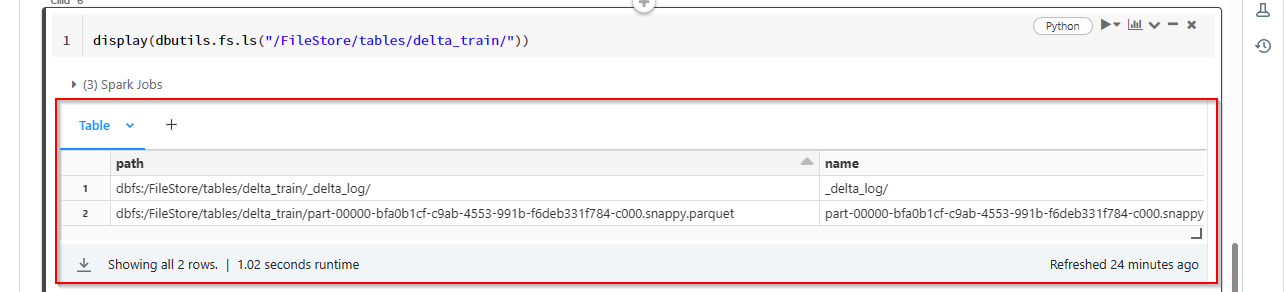
I reproduce same in my environment as per above code .I got this output.