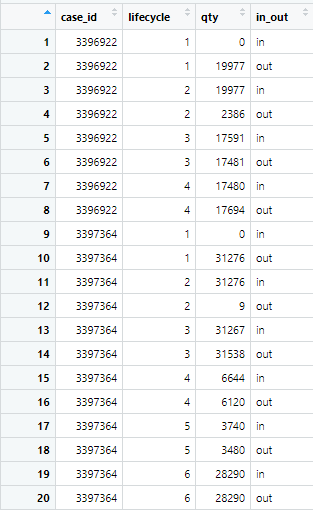
I have the dataframe below and I want to find the sum qty of unique case_id for the max lifecycle that it has when the in_out value is out. That means that I will add for this case 17694 and 28290
lifes<-structure(list(case_id = c(3396922, 3396922, 3396922, 3396922,
3396922, 3396922, 3396922, 3396922, 3397364, 3397364, 3397364,
3397364, 3397364, 3397364, 3397364, 3397364, 3397364, 3397364,
3397364, 3397364), lifecycle = c(1, 1, 2, 2, 3, 3, 4, 4, 1, 1,
2, 2, 3, 3, 4, 4, 5, 5, 6, 6), qty = c(0, 19977, 19977, 2386,
17591, 17481, 17480, 17694, 0, 31276, 31276, 9, 31267, 31538,
6644, 6120, 3740, 3480, 28290, 28290), in_out = c("in", "out",
"in", "out", "in", "out", "in", "out", "in", "out", "in", "out",
"in", "out", "in", "out", "in", "out", "in", "out")), row.names = c(NA,
-20L), case_id = "case_id", activity_id = "activity", activity_instance_id = "action", lifecycle_id = "registration_type", resource_id = "resource", timestamp = "timestamp", class = c("eventlog",
"log", "tbl_df", "tbl", "data.frame"))
CodePudding user response:
Here's one way -
library(dplyr)
lifes %>%
filter(in_out == 'out') %>%
group_by(case_id) %>%
summarise(max_value = qty[which.max(lifecycle)]) %>%
pull(max_value) %>% sum()
#[1] 45984
If you run only till summarise step you can see the max_value for each case_id -
lifes %>%
filter(in_out == 'out') %>%
group_by(case_id) %>%
summarise(max_value = qty[which.max(lifecycle)])
# case_id max_value
# <dbl> <dbl>
#1 3396922 17694
#2 3397364 28290
CodePudding user response:
does this work for you?
library(dplyr)
lifes |>
group_by(case_id, in_out) |>
mutate(lifecycle_is_max = lifecycle == max(lifecycle)) |>
group_by(in_out, lifecycle_is_max) |>
summarise(x = sum(qty))
CodePudding user response:
This works using dplyr package :
library(dplyr)
lifes %>%
filter(in_out == "out") %>%
arrange(-lifecycle) %>%
filter(duplicated(case_id) == F) %>%
sum()