Good day all!
Excuse my title being vague but I am having trouble expressing my desire concisely and, consequently, I don't know the proper terms to google.
I have data like this:
df <- tibble(
PersonID = c(1:10),
Location = c("Atlanta", "Chicago", "Denver", "Baltimore", "Baltimore", "Atlanta", "Denver", "Chicago", "Atlanta", "Baltimore"),
Success = c(1, 1, 0, 0, 1, 0, 0, 1, 1, 0)
)
What I want, eventually, should be simple. I want the Locations to be columns and one row underneath with the number of events per Location and the proportion of successful attempts.
| Atlanta | Baltimore | Chicago | Denver |
| --------| --------- | ------- | ------ |
| 2 (66.7)| 1 (33.3) | 2 (100) | 0 (0) |
I know a bit of library(gt) but to no avail. I have no preferences towards any package so feel free to suggest any solution.
Thank you all very much!
P. S.: I would like to tip you a coffee :-)
CodePudding user response:
Here's a way to format the data in desired format using dplyr and tidyr.
We create a summarising function (sum_and_prop) and apply it to every Location while getting the data in wide format using pivot_wider.
library(dplyr)
library(tidyr)
sum_and_prop <- function(x) {
sprintf('%d (%.1f)', sum(x), mean(x) * 100)
}
result <- df %>%
arrange(Location) %>%
pivot_wider(id_cols = -PersonID, names_from = Location,
values_from = Success, values_fn = sum_and_prop)
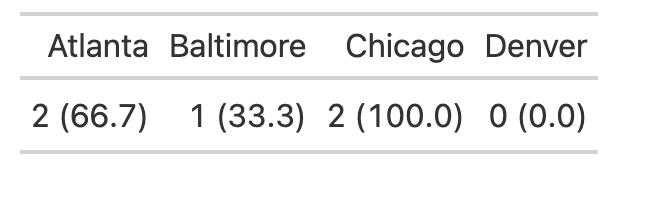
result
# Atlanta Baltimore Chicago Denver
# <chr> <chr> <chr> <chr>
#1 2 (66.7) 1 (33.3) 2 (100.0) 0 (0.0)
The output of this can be passed to gt or any other library of your choice.
gt::gt(result)
CodePudding user response:
They are multiple possibilities depending on the package you use for export (gt, flextable, etc.). Do you need MS Office export ? HTML ? PDF ? Is it to be used inside a Quarto/Rmarkdown document ? These questions might help to find the package that better suits your needs with parameters such as decimal and thousand separators,text align...
Here is some code to get the expected output in the console:
library(tidyverse)
df <- tibble(
PersonID = c(1:10),
Location = c("Atlanta", "Chicago", "Denver", "Baltimore", "Baltimore", "Atlanta", "Denver", "Chicago", "Atlanta", "Baltimore"),
Success = c(1, 1, 0, 0, 1, 0, 0, 1, 1, 0)
)
df %>%
group_by(Location) %>%
summarise(n = n(),
success_rate = sum(Success)/n) %>%
ungroup() %>%
mutate(label = paste(n, paste0("(", round(success_rate, 2), ")"))) %>%
select(Location, label) %>%
pivot_wider(names_from = Location, values_from = label)
#> # A tibble: 1 × 4
#> Atlanta Baltimore Chicago Denver
#> <chr> <chr> <chr> <chr>
#> 1 3 (0.67) 3 (0.33) 2 (1) 2 (0)
Created on 2023-01-31 with reprex v2.0.2