I have a pandas DataFrame as shown below. The columns are date, color, time, and duration (in seconds). I need to calculate the amount of time throughout a day that we are displaying a color.
date color start time duration(seconds)
2021-07-06 RED 11:00:00.00 5
2021-07-06 RED 11:00:00.00 9
2021-07-06 BLUE 11:00:00.00 3
2021-07-06 RED 11:00:00.00 3
2021-07-06 BLUE 12:00:00.00 10
2021-07-06 BLUE 12:00:00.00 7
2021-07-06 RED 12:00:00.00 9
2021-07-06 BLUE 12:00:00.00 5
2021-07-06 RED 12:00:00.00 1
2021-07-06 RED 12:00:00.00 2
For example, in a 24 hour day I need to understand how long we are displaying a color. There will be a variable number of colors each day, staggered start times, and varying durations.
If we're looking at the color red in the example above, the duration of displaying red would be 18 seconds. We don't double count any display overlaps.
My desired output would be a DataFrame which tells me how long each color was displayed for, and how long all colors were displayed. The maximum amount of time for each color, or any color can only be 24 hours. For the example above, the answer would be:
Red Duration: 18 seconds
Blue Duration: 13 seconds
Total Duration: 19 seconds
How would I go about doing this?
CodePudding user response:
Each row in your data corresponds to an interval. For any colour, how many intervals overlap a point in time is a step function. A package called staircase has been built upon pandas and numpy for analysis with step functions.
setup
I'm going to use different data, to highlight that this approach works with staggered start times (which your example doesn't have). I'm also combining date and start time to simplify
df = pd.DataFrame(
{
"color":["RED", "RED","BLUE","RED","BLUE","BLUE","RED","BLUE","RED","RED"],
"start":[
pd.Timestamp("2021-07-06 11:00:00"),
pd.Timestamp("2021-07-06 11:00:02"),
pd.Timestamp("2021-07-06 11:00:01"),
pd.Timestamp("2021-07-06 11:00:04"),
pd.Timestamp("2021-07-06 11:00:05"),
pd.Timestamp("2021-07-06 11:00:05"),
pd.Timestamp("2021-07-06 11:00:08"),
pd.Timestamp("2021-07-06 11:00:07"),
pd.Timestamp("2021-07-06 11:00:12"),
pd.Timestamp("2021-07-06 11:00:14"),
],
"duration":[5,4,7,3,4,6,4,7,2,3]
}
)
df["end"] = df["start"] pd.to_timedelta(df["duration"], "s")
solution
We'll create a step function for each colour. A step function is represented by the staircase.Stairs class. This class is to staircase as Series is to pandas. To do this we group the dataframe on this variable and pass the sub-dataframes to the 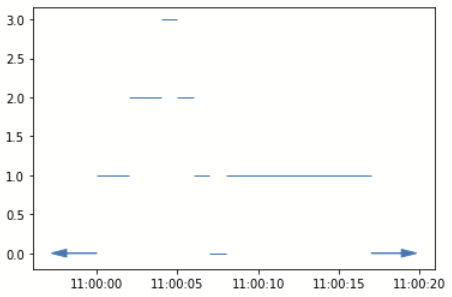
Since you do not want to count overlaps, we need to convert each step function to a boolean valued one - i.e. if it is non zero set it to 1.
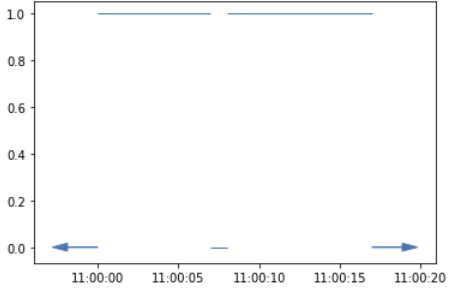
stepfunctions = stepfunctions.apply(sc.Stairs.make_boolean)
Now plotting the step function for RED again gives us
What you are wanting to do is create bins and integrate (find the area under) these step functions. For a step function sf this means the following calculation. Let's say your bins are 5 second bins, (as opposed to daily), just to make it interesting
bins = pd.date_range(pd.Timestamp("2021-07-06 11:00:00"), freq = "5s", periods=4)
bin_sums = stepfunctions.apply(lambda sf: sf.slice(bins).integral())
This gives you a dataframe, indexed by color, with columns for each bin. We'll melt it to display it better
bin_sums.melt(var_name="bin", ignore_index=False)
color bin value
BLUE [2021-07-06 11:00:00, 2021-07-06 11:00:05) 0 days 00:00:04
RED [2021-07-06 11:00:00, 2021-07-06 11:00:05) 0 days 00:00:05
TOTAL [2021-07-06 11:00:00, 2021-07-06 11:00:05) 0 days 00:00:05
BLUE [2021-07-06 11:00:05, 2021-07-06 11:00:10) 0 days 00:00:05
RED [2021-07-06 11:00:05, 2021-07-06 11:00:10) 0 days 00:00:04
TOTAL [2021-07-06 11:00:05, 2021-07-06 11:00:10) 0 days 00:00:05
BLUE [2021-07-06 11:00:10, 2021-07-06 11:00:15) 0 days 00:00:04
RED [2021-07-06 11:00:10, 2021-07-06 11:00:15) 0 days 00:00:05
TOTAL [2021-07-06 11:00:10, 2021-07-06 11:00:15) 0 days 00:00:05
So this approach
- handles overlaps
- handles intervals crossing bin boundaries
CodePudding user response:
There is a solution, similar to the one with staircase which involves interval arrays instead of step functions. It uses a package piso which is built for set operations with pandas interval classes
setup
Assume the same setup as staircase solution
solution
For each colour create pandas.arrays.IntervalArrays (or pandas.IntervalIndex)
import piso
interval_arrays = df.groupby("color").apply(lambda d: pd.arrays.IntervalArray.from_arrays(d["start"], d["end"]))
interval_arrays looks like this
color
BLUE [(2021-07-06 11:00:01, 2021-07-06 11:00:08], (...
RED [(2021-07-06 11:00:00, 2021-07-06 11:00:05], (...
dtype: object
We need to create the union of these intervals in each array
interval_arrays = interval_arrays.apply(piso.union)
We then create the union of these two arrays to get the total
interval_arrays["TOTAL"] = piso.union(*interval_arrays)
interval_arrays looks like this
color
BLUE [(2021-07-06 11:00:01, 2021-07-06 11:00:08], (...
RED [(2021-07-06 11:00:00, 2021-07-06 11:00:05], (...
TOTAL [(2021-07-06 11:00:00, 2021-07-06 11:00:17]]
dtype: object
create bins as a pandas.IntervalIndex
bins = pd.date_range(pd.Timestamp("2021-07-06 11:00:00"), freq = "5s", periods=4)
ii_bins = pd.IntervalIndex.from_breaks(bins)
Then use piso.coverage() which takes an interval array, and a domain, and returns the fraction of the domain (i.e. bin) covered by the intervals in the array. If we multiply the fraction by the bin size then it will be the total time
interval_arrays.apply(lambda ia: pd.Series([piso.coverage(ia, bin)*bin.length for bin in ii_bins]))
This results in a dataframe
color 0 1 2
BLUE 0 days 00:00:04 0 days 00:00:05 0 days 00:00:04
RED 0 days 00:00:05 0 days 00:00:04 0 days 00:00:05
TOTAL 0 days 00:00:05 0 days 00:00:05 0 days 00:00:05
columns are bin indices. You can switch them out for the intervals ii_bins if you want to, and perhaps melt the dataframe to get tidy data.
This approach also handles overlaps and handles intervals crossing bin boundaries.
CodePudding user response:
This achieves your desired result, which seems to be the sum of the max duration of each color by time and date:
df.groupby(["date", "color", "start_time"])["duration(seconds)"].max().groupby("color").sum()
Output:
color
BLUE 13
RED 18
Name: duration(seconds), dtype: int64
To get the total sum of the max duration grouped by time:
df.groupby(["date", "start_time"])["duration(seconds)"].max().sum()
Output:
19