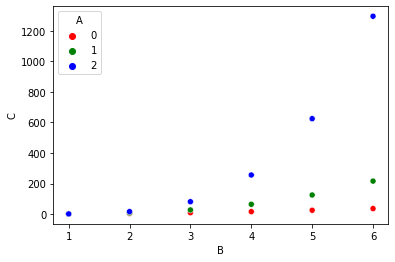
I have three-column data in a file named "sample1.dat" and a code that reads the columns and tries to plot the 3rd column against the 2nd column. I pick up parameter values from the 1st column elements as long as their values remain the same.
"sample1.dat" reads
0 1 1
0 2 4
0 3 9
0 4 16
0 5 25
0 6 36
1 1 1
1 2 8
1 3 27
1 4 64
1 5 125
1 6 216
2 1 1
2 2 16
2 3 81
2 4 256
2 5 625
2 6 1296
And my code:
import matplotlib.pyplot as plt
import numpy as np
data = np.loadtxt('sample1.dat')
x = data[:,0]
y = data[:,1]
z = data[:,2]
L = len(data)
col = ['r','g','b']
x0 = x[0]; j=0; jold=-1
for i in range(L):
print('j, col[j]=',j, col[j])
if x[i] == x0:
print('y[i], z[i]=',y[i],z[i])
if i==0 or j != jold: # j-index decides new or the same paramet
label = 'parameter = {}'.format(x0)
else:
label = ''
print('label =',label)
plt.plot(y[i], z[i], color=col[j], marker='o', label=label)
else:
x0 = x[i] # Update when x-value changes,
# i.e. pick up the next parameter value
i -= 1 # Shift back else we miss the 1st point for new x-value
j = 1; jold = j
plt.legend()
plt.xlabel('2nd column')
plt.ylabel('3rd column')
plt.savefig('sample1.png')
plt.show()
The plot outcome:
One can clearly see that two issues persist:
The legends appear only for the first parameter though I tried to avoid the repitition in my code.
The default linestyle is not appearing though the legends show line plus marker plots.
How could I resolve these or is there a smarter way of coding to fulfill the same purpose.
CodePudding user response:
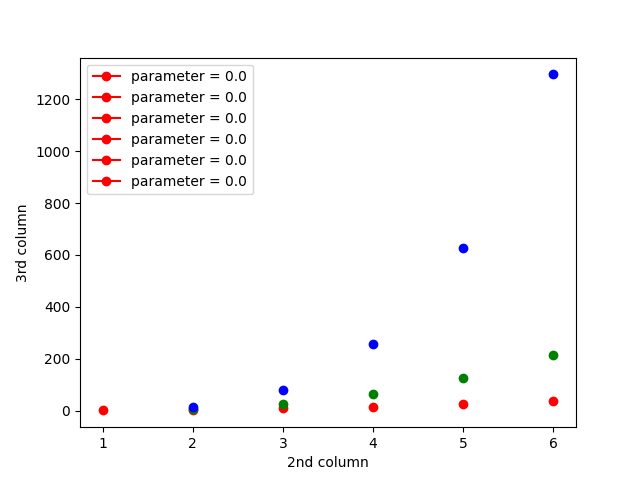
The first issue is due to some strange logic involving j,jold and x0. The code can be simplified by drawing all y,z for each x-value at once. Numpy allows selecting the y's corresponding to a given x0 as y[x==x0s].
The second issue can be solved by explicitly setting the desired linestyle, i.e. ls=''.
import matplotlib.pyplot as plt
import numpy as np
data = np.loadtxt('sample1.dat')
x = data[:, 0]
y = data[:, 1]
z = data[:, 2]
colors = ['r', 'g', 'b']
for x0, color in zip(np.unique(x), colors):
plt.plot(y[x == x0], z[x == x0], color=color, marker='o', ls='', label=f'parameter = {x0:.0f}')
plt.legend()
plt.xlabel('2nd column')
plt.ylabel('3rd column')
plt.show()
CodePudding user response:
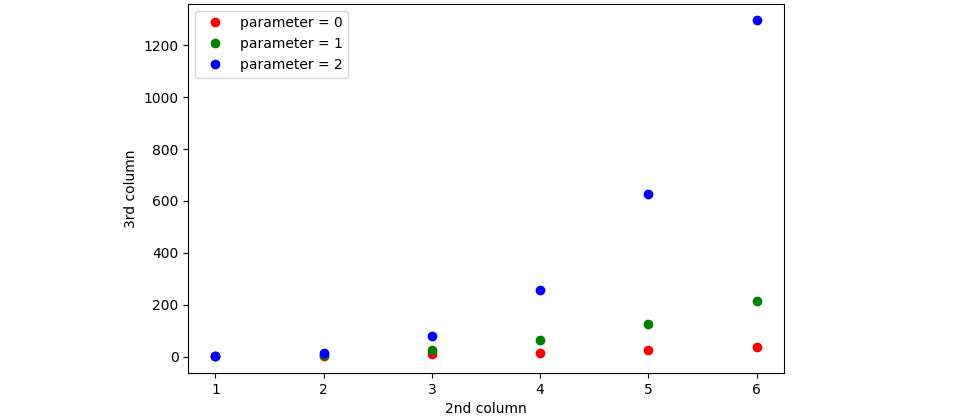
You can get the result you want in a few line by using pandas and seaborn.
If you add column names (for instance A, B, and C) to the data in the sample1.dat file as follow:
A B C
0 1 1
0 2 4
0 3 9
0 4 16
0 5 25
0 6 36
1 1 1
1 2 8
1 3 27
1 4 64
1 5 125
1 6 216
2 1 1
2 2 16
2 3 81
2 4 256
2 5 625
2 6 1296
You can then load your data in a pandas dataframe and plot it with seaborn as follow:
import pandas as pd
import seaborn as sns
df=pd.read_fwf('sample1.dat')
col = ['r','g','b']
sns.scatterplot(data=df,x='B',y='C',hue='A',palette=col)
And the output gives: