I am trying to change my data from wide to long format.
It currently looks like this:

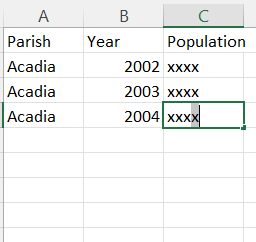
And I would like it to look like:
This is my current code but does not seem to be working:
gather(parishpop, key= “New_var_name”, value= “var_value”, X2002, X2003, X2004, X2005, X2006, X2007, X2008, X2009, X2010, X2011, X2012, X2013, X2014, X2015, X2016, X2017, X2018, X2019, X2020)
CodePudding user response:
Update: A better version using dplyr and tidyr only:
df %>%
pivot_longer(
-Parish,
names_to = "Year",
values_to = "Population",
names_pattern = 'X(\\d )',
names_transform = list(Year = as.integer))
)
Parish Year Population
<chr> <int> <int>
1 Acadia 2002 59244
2 Acadia 2003 59541
3 Acadia 2004 59839
4 Acadia 2005 60138
5 Acadia 2006 58697
6 Acadia 2007 59958
7 Acadia 2008 62194
8 Acadia 2009 63015
9 Acadia 2010 61877
10 Acadia 2011 61865
# ... with 134 more rows
First answer:
We could first pivot_longer then remove the X in Year. Here we have used parse_number from readr package which I personally use often!
library(tidyverse)
df %>%
pivot_longer(
-Parish,
names_to = "Year",
values_to = "Population"
) %>%
mutate(Year = parse_number(Year))
Parish Year Population
<chr> <dbl> <int>
1 Acadia 2002 59244
2 Acadia 2003 59541
3 Acadia 2004 59839
4 Acadia 2005 60138
5 Acadia 2006 58697
6 Acadia 2007 59958
7 Acadia 2008 62194
8 Acadia 2009 63015
9 Acadia 2010 61877
10 Acadia 2011 61865
# ... with 134 more rows
data:
df <- structure(list(Parish = c("Acadia", "Allen", "Ascension", "Assumption",
"Avoyelles", "Beauregard", "Bienville", "Bossier", "Caddo"),
X2002 = c(59244L, 24552L, 71862L, 23479L, 41889L, 32655L,
16253L, 95247L, 249944L), X2003 = c(59541L, 24675L, 72222L,
23596L, 42099L, 32819L, 16334L, 95724L, 251195L), X2004 = c(59839L,
24798L, 72583L, 23714L, 42310L, 32983L, 16416L, 96203L, 252452L
), X2005 = c(60138L, 24922L, 72946L, 23833L, 42521L, 33148L,
16498L, 96684L, 253715L), X2006 = c(58697L, 21435L, 94128L,
23361L, 41954L, 33009L, 15626L, 101918L, 254092L), X2007 = c(59958L,
25524L, 99056L, 22991L, 42169L, 34776L, 14907L, 108705L,
252609L), X2008 = c(62194L, 26178L, 100132L, 24146L, 43889L,
36139L, 15604L, 110352L, 260391L), X2009 = c(63015L, 26523L,
101453L, 24465L, 44468L, 36616L, 15810L, 111808L, 263826L
), X2010 = c(61877L, 25702L, 107890L, 23333L, 42106L, 35831L,
14306L, 117675L, 255590L), X2011 = c(61865L, 25740L, 110075L,
23185L, 41795L, 36090L, 14261L, 120134L, 256967L), X2012 = c(61997L,
25622L, 112218L, 23072L, 41572L, 36333L, 14192L, 123160L,
257252L), X2013 = c(62299L, 25664L, 114636L, 23199L, 41275L,
36260L, 13961L, 124021L, 255127L), X2014 = c(62667L, 25714L,
117282L, 23047L, 41088L, 36239L, 13782L, 124868L, 252605L
), X2015 = c(62679L, 25631L, 119374L, 22898L, 40979L, 36531L,
13823L, 125554L, 251345L), X2016 = c(62786L, 25680L, 121558L,
22756L, 40983L, 36973L, 13780L, 125920L, 248837L), X2017 = c(62559L,
25583L, 123177L, 22568L, 40836L, 36847L, 13631L, 126959L,
245935L)), class = "data.frame", row.names = c(NA, -9L))
CodePudding user response:
library(data.table)
setDT(df)
# wide to long
melt(df
, id.vars = "i..Parish"
, measure.vars = patterns("^X")
, variable.name = 'Year'
, value.name = "Population"
)[, Year := gsub('X', '', Year)][]