I have a dataset with ~ 150 countries, a grouping variable, and a value for each country and group (0-6). I am trying to show, that countries with a higher GDP get higher values in one group than the other. I made a scatterplot showing the values for each country by group (the countries are sorted by GDP). I want to draw a line around the points, so it becomes more aparent which group has higher values in which range of GDP. I am however, at a loss.
data %>% ggplot(aes(x = fct_rev(fct_inorder(country)),
y = count, color = group))
geom_point()

I need to clean it up, obviously, but does someone know how to do this, density does not work due to the factor on the x axis, line does not work either, as it goes to every single point. Simulating continous data on the basis of my current dataset would work as well (I just cant figure out how to do that). I just want to highlight the value ranges based by group and GDP. Maybe a different type of plot might help, but which? All comments appreciated! My data is below, it is sorted by GDP already
structure(list(count = c(1, 0, 1, 3, 0, 1, 0, 1, 0, 1, 0, 2,
2, 0, 1, 0, 0, 2, 3, 0, 0, 1, 0, 2, 2, 0, 1, 0, 1, 0, 0, 1, 1,
0, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 0, 1, 1, 0, 1, 0, 0, 1, 2, 0,
0, 1, 2, 0, 0, 6, 1, 1, 1, 0, 2, 1, 1, 0, 4, 2, 1, 0, 2, 4, 0,
1, 1, 0, 2, 1, 2, 1, 0, 2, 0, 1, 2, 1, 0, 2, 3, 2, 1, 0, 1, 1,
2, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 0, 1, 0, 1, 1, 4, 0, 2, 0,
2, 0, 2, 0, 1, 1, 1, 1, 1, 5, 0, 0, 3, 3, 0, 0, 2, 1, 2, 0, 2,
1, 0, 0, 2, 1, 0, 1, 2, 3, 0, 0, 1, 4, 0, 0, 3, 0, 1, 0, 2, 4,
0, 1, 0, 0, 2, 0, 1, 0, 2, 0, 2, 0, 2, 0, 2, 0, 1, 0, 2, 0, 1,
0, 1, 1, 2, 0, 1, 1, 1, 0, 2, 0, 2, 0, 3, 1, 0, 4, 0, 2, 0, 0,
1, 1, 0, 0, 1, 0, 2, 0, 2, 0, 1, 0, 1, 0, 1, 0, 2, 2, 0), country = c("CHE",
"CHE", "NOR", "NOR", "IRL", "IRL", "SGP", "SGP", "USA", "USA",
"AUS", "AUS", "DNK", "DNK", "SWE", "SWE", "NLD", "NLD", "GBR",
"GBR", "SCT", "SCT", "FIN", "FIN", "CAN", "CAN", "DEU", "DEU",
"BEL", "BEL", "ARE", "ARE", "JPN", "JPN", "ITA", "ITA", "KOR",
"KOR", "BRN", "BRN", "SVN", "SVN", "BHR", "BHR", "PRT", "PRT",
"SAU", "SAU", "EST", "EST", "GRC", "GRC", "LTU", "LTU", "SYC",
"SYC", "LVA", "LVA", "CHL", "CHL", "HRV", "HRV", "CRI", "CRI",
"TUR", "TUR", "MYS", "MYS", "KAZ", "KAZ", "LCA", "LCA", "ROU",
"ROU", "MUS", "MUS", "GRD", "GRD", "MEX", "MEX", "RUS", "RUS",
"CHN", "CHN", "SUR", "SUR", "BRA", "BRA", "DOM", "DOM", "BGR",
"BGR", "MNE", "MNE", "THA", "THA", "COL", "COL", "SRB", "SRB",
"ZAF", "ZAF", "GUY", "GUY", "FJI", "FJI", "LBY", "LBY", "BIH",
"BIH", "AZE", "AZE", "MKD", "MKD", "JAM", "JAM", "IRQ", "IRQ",
"NAM", "NAM", "GEO", "GEO", "ALB", "ALB", "XKX", "XKX", "WSM",
"WSM", "LKA", "LKA", "JOR", "JOR", "ARM", "ARM", "EGY", "EGY",
"SWZ", "SWZ", "IDN", "IDN", "PSE", "PSE", "CPV", "CPV", "MDA",
"MDA", "MAR", "MAR", "VUT", "VUT", "PNG", "PNG", "NGA", "NGA",
"LAO", "LAO", "VNM", "VNM", "SLB", "SLB", "GHA", "GHA", "MRT",
"MRT", "KEN", "KEN", "PAK", "PAK", "BGD", "BGD", "HTI", "HTI",
"ZMB", "ZMB", "SEN", "SEN", "YEM", "YEM", "SDN", "SDN", "TLS",
"TLS", "KGZ", "KGZ", "BEN", "BEN", "TJK", "TJK", "TZA", "TZA",
"EAZ", "EAZ", "NPL", "NPL", "GIN", "GIN", "UGA", "UGA", "MLI",
"MLI", "ETH", "ETH", "BFA", "BFA", "GMB", "GMB", "LBR", "LBR",
"GNB", "GNB", "SLE", "SLE", "MOZ", "MOZ", "AFG", "AFG", "COD",
"COD", "MWI", "MWI"), group = c(1, 2, 2, 1, 2, 1, 1, 2, 1, 2,
2, 1, 1, 2, 1, 2, 2, 1, 1, 2, 2, 1, 2, 1, 1, 2, 1, 2, 1, 2, 1,
2, 1, 2, 1, 2, 1, 2, 1, 2, 2, 1, 1, 2, 2, 1, 1, 2, 1, 2, 2, 1,
1, 2, 1, 2, 1, 2, 2, 1, 1, 2, 1, 2, 1, 2, 2, 1, 1, 2, 2, 1, 1,
2, 1, 2, 2, 1, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 2, 1, 1, 2, 1, 2,
1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 2, 1, 1, 2, 2, 1, 1, 2, 1, 2, 1,
2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 2, 1, 1, 2, 2, 1, 1, 2, 1, 2,
1, 2, 1, 2, 1, 2, 2, 1, 1, 2, 2, 1, 1, 2, 2, 1, 1, 2, 1, 2, 1,
2, 2, 1, 2, 1, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2,
1, 2, 1, 2, 2, 1, 1, 2, 2, 1, 1, 2, 1, 2, 1, 2, 2, 1, 2, 1, 2,
1, 1, 2, 2, 1, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 2, 1
)), row.names = c(33L, 34L, 151L, 152L, 89L, 90L, 175L, 176L,
205L, 206L, 9L, 10L, 49L, 50L, 187L, 188L, 149L, 150L, 65L, 66L,
169L, 170L, 61L, 62L, 31L, 32L, 47L, 48L, 13L, 14L, 5L, 6L, 99L,
100L, 93L, 94L, 107L, 108L, 29L, 30L, 185L, 186L, 23L, 24L, 159L,
160L, 167L, 168L, 57L, 58L, 77L, 78L, 119L, 120L, 191L, 192L,
121L, 122L, 35L, 36L, 83L, 84L, 45L, 46L, 199L, 200L, 143L, 144L,
101L, 102L, 115L, 116L, 163L, 164L, 139L, 140L, 79L, 80L, 127L,
128L, 165L, 166L, 37L, 38L, 183L, 184L, 27L, 28L, 51L, 52L, 21L,
22L, 133L, 134L, 193L, 194L, 41L, 42L, 181L, 182L, 217L, 218L,
81L, 82L, 63L, 64L, 113L, 114L, 25L, 26L, 11L, 12L, 129L, 130L,
95L, 96L, 91L, 92L, 145L, 146L, 67L, 68L, 3L, 4L, 213L, 214L,
211L, 212L, 117L, 118L, 97L, 98L, 7L, 8L, 55L, 56L, 189L, 190L,
87L, 88L, 161L, 162L, 43L, 44L, 125L, 126L, 123L, 124L, 209L,
210L, 157L, 158L, 147L, 148L, 109L, 110L, 207L, 208L, 177L, 178L,
69L, 70L, 137L, 138L, 103L, 104L, 155L, 156L, 19L, 20L, 85L,
86L, 219L, 220L, 173L, 174L, 215L, 216L, 171L, 172L, 197L, 198L,
105L, 106L, 15L, 16L, 195L, 196L, 201L, 202L, 53L, 54L, 153L,
154L, 71L, 72L, 203L, 204L, 131L, 132L, 59L, 60L, 17L, 18L, 73L,
74L, 111L, 112L, 75L, 76L, 179L, 180L, 135L, 136L, 1L, 2L, 39L,
40L, 141L, 142L), class = "data.frame")
CodePudding user response:
Here's one idea to help visualize the difference you are trying to show. Firstly, the country names on the x axis are likely to remain illegible however you try to label them. It might therefore be better to have the rank of the countries on the x axis.
Drawing a polygon around the points might make the point visually, but doesn't make much sense in statistical terms. What might be better here is to plot a regression with a separate line for each group. Since we are dealing with count data, we can use Poisson regression, and since we have a numeric rank on the x axis, it is possible to have lines going across your plot to show the regression.
library(ggplot2)
library(dplyr)
library(forcats)
data %>%
mutate(group = factor(group),
country = fct_rev(fct_inorder(country)),
rank = as.numeric(country)) %>%
ggplot(aes(rank, count, colour = group))
geom_point(position = position_jitter(width = 0.1, height = 0.05),
alpha = 0.5)
geom_smooth(formula = y ~ x, method = glm,
method.args = list(family = poisson), alpha = 0.2,
aes(fill = after_scale(colour)))
theme_bw()
scale_colour_manual(values = c("orange", "deepskyblue4"))
ggtitle("Counts per group according to per capita GDP")
labs(x = "Country rank by GDP per capita",
y = "Count (jittered for clarity)")
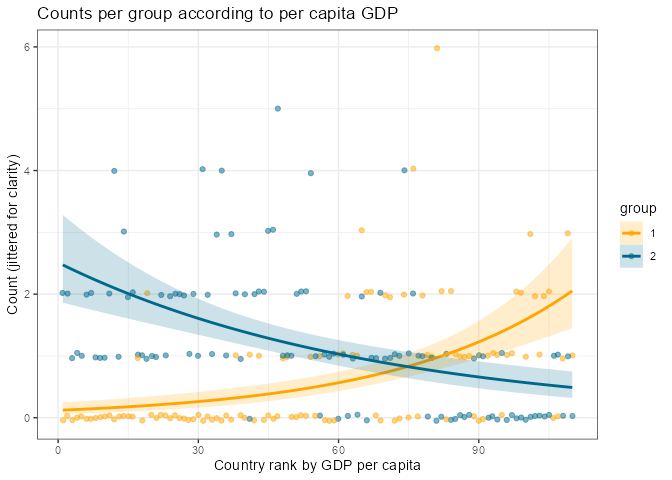
I think this plot makes the point quite well. For clarity, I might add a couple of labels for countries to help orient your audience to the scale.
If you really want polygons drawn around the points, then it would probably be best to draw the convex hull around each set, which you could do like this:
data <- data %>%
mutate(group = factor(group),
country = fct_rev(fct_inorder(country)),
rank = as.numeric(country))
hull <- data %>%
group_by(group) %>%
slice(chull(rank, count))
ggplot(data, aes(rank, count))
geom_polygon(aes(colour = group, fill = after_scale(colour)),
alpha = 0.3, data = hull)
geom_point(aes(colour = group))
theme_bw()
scale_colour_manual(values = c("orange", "deepskyblue4"))
ggtitle("Counts per group according to per capita GDP")
labs(x = "Country rank by GDP per capita",
y = "Count (jittered for clarity)")
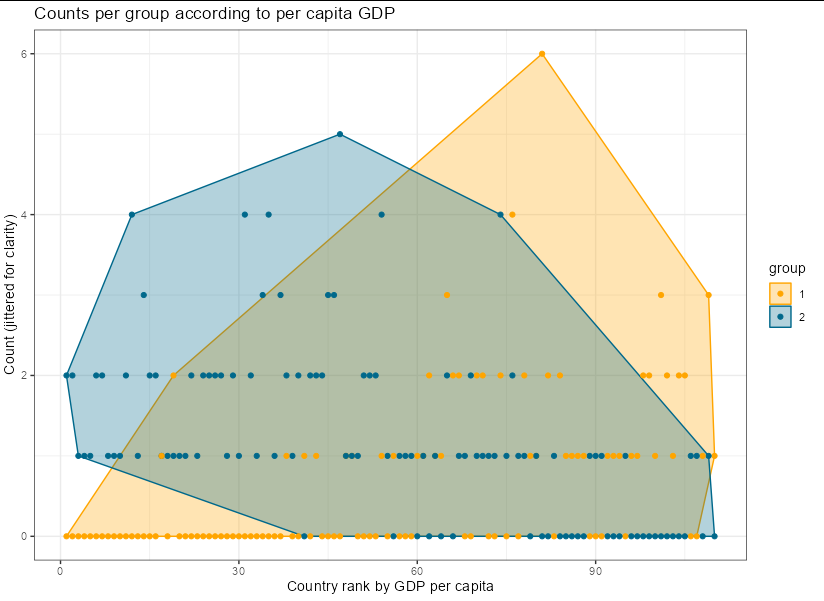
Although as I say, this doesn't have much statistical meaning.
One other thought is that you can pivot the dataframe and find the difference in counts between group 1 and group 2, then show the trend line over the ranked countries:
library(tidyr)
data %>%
mutate(group = factor(group),
country = fct_inorder(country),
rank = as.numeric(country)) %>%
pivot_wider(names_from = group, values_from = count) %>%
mutate(difference = `1` - `2`) %>%
ggplot(aes(rank, difference))
geom_hline(yintercept = 0, linetype = 2)
geom_point()
geom_smooth(aes(group = 1), method = lm, formula = y~x,
colour = "red", fill = "orange", alpha = 0.2)
theme_bw()
ggtitle("Counts per group according to per capita GDP")
labs(x = "Country rank by GDP per capita",
y = "Difference in counts between group 1 and group 2")
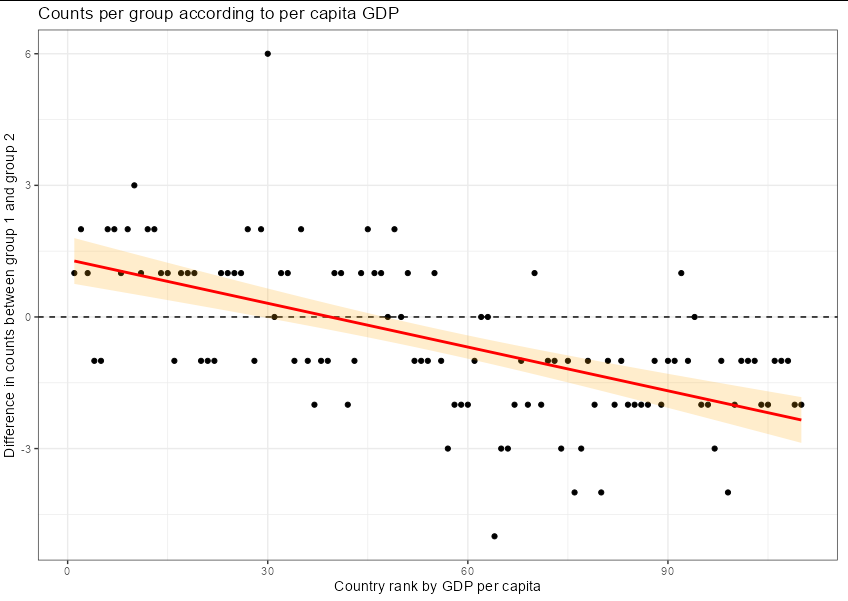
This has the benefit that you can label individual countries more easily, and very clearly shows the relationship you want to demonstrate.
Created on 2022-03-05 by the reprex package (v2.0.1)