I am using a gender-pay gap data from Glassdoor which is accessible from 
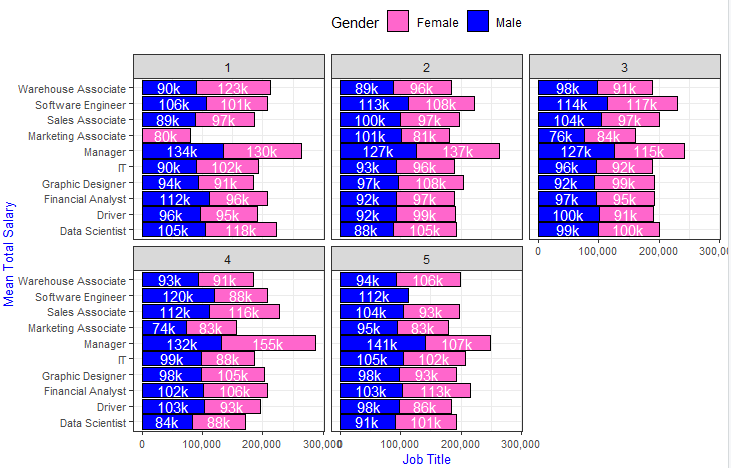
What I want to show is to label the mean total salary for male and female employees and for each job title separately on the pink and blue colored bars.
Any help would be appreciated
CodePudding user response:
In terms of comparing salaries by gender, a side-by-side comparison seems more practical (as already pointed out in the comments).
Nevertheless - regarding the technical question of positioning the labels, here is one way of doing it. The tricky part is finding the center positions of the stacked bars.
library(tidyverse)
df <- readr::read_csv("~/data.csv")
df_summary <- df %>%
group_by(gender, jobTitle, perfEval) %>%
summarize(totalcomp = mean(basePay bonus),
totalcomp_label = paste0(round(totalcomp * 1e-3, 0), "k")) %>%
ungroup()
df_plot <- df_summary %>%
left_join(
# the messy part to find approriate label positions - there may be a solution with less pivoting steps
df_summary %>%
tidyr::pivot_wider(id_cols = c(jobTitle, perfEval),
values_from = "totalcomp", names_from = "gender", values_fill = 0) %>%
dplyr::mutate(labelpos_M = Male/2, labelpos_F = Male Female/2) %>%
tidyr::pivot_longer(c(Female, Male), names_to = "gender") %>%
dplyr::mutate(
labelpos = case_when(gender == "Male" ~ labelpos_M,
gender == "Female" ~ labelpos_F,
TRUE ~ NA_real_)
) %>%
dplyr::select(jobTitle, perfEval, gender, labelpos),
by = c("jobTitle", "perfEval", "gender")
)
# A tibble: 98 x 6
# gender jobTitle perfEval totalcomp totalcomp_label labelpos
# <chr> <chr> <dbl> <dbl> <chr> <dbl>
# 1 Female Data Scientist 1 118479. 118k 164089.
# 2 Female Data Scientist 2 105040. 105k 140556.
# 3 Female Data Scientist 3 100275. 100k 149580.
# 4 Female Data Scientist 4 87633. 88k 127996.
# 5 Female Data Scientist 5 101449. 101k 142046.
df_plot %>%
ggplot()
geom_col(aes(y = jobTitle, x = totalcomp, fill = gender), width = 0.9, color = "black")
theme_bw()
labs(x = "Job Title", y = "Mean Total Salary", fill = "Gender")
theme(axis.title = element_text(size = 10, color = "blue"),
axis.text = element_text(size = 8),
legend.position = "top")
scale_fill_manual(values = c("#FF66CC", "blue"))
scale_x_continuous(labels = scales::comma)
facet_wrap( ~ perfEval)
# positioning the labels
geom_text(aes(x = labelpos, y = jobTitle, label = totalcomp_label),
color = "white")