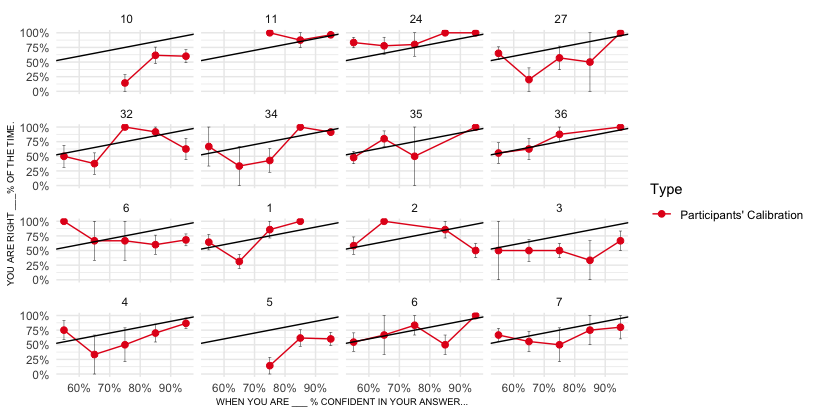
I have created a game to see how confidence correlates with knowledge. Here is a print out of the first few participants.
It would be easier to decipher the data (to see if participants are overconfident or not) if each of these graphs had a line showing what perfect calibration looked like (55% of questions right when one is 55% confident, 65% right when 65% confident, and so on). This would be a straight line, that shows that values that fall below it are a result of overconfidence. The problem is that I don't have data for such a line, it is more for analysis purposes. Does anyone know an easy way to plot a line that isn't included in the dataset, and how to do that to each graph in a facet_wrap?
Here is the dataframe:
df <- structure(list(Confidence = c("55", "55", "55", "55", "55", "55",
"55", "55", "55", "55", "55", "55", "55", "65", "65", "65", "65",
"65", "65", "65", "65", "65", "65", "65", "65", "65", "75", "75",
"75", "75", "75", "75", "75", "75", "75", "75", "75", "75", "75",
"75", "75", "85", "85", "85", "85", "85", "85", "85", "85", "85",
"85", "85", "85", "85", "85", "95", "95", "95", "95", "95", "95",
"95", "95", "95", "95", "95", "95", "95", "95", "95"),
Type = c("Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration", "Participants' Calibration"),
Participant = c("1", "3", "4", "2", " 24", " 27", " 32", " 34",
" 35", " 36", " 6", "7", "6", "1", "3", "4", "2", " 24", " 27",
" 32", " 34", " 35", " 36", " 6", "7", "6", "1", "3", "4", "5",
" 10", " 11", " 24", " 27", " 32", " 34", " 35", " 36", " 6",
"7", "6", "1", "3", "4", "5", "2", " 10", " 11", " 24", " 27",
" 32", " 34", " 6", "7", "6", "3", "4", "5", "2", " 10", " 11",
" 24", " 27", " 32", " 34", " 35", " 36", " 6", "7", "6"),
Accuracy = c(0.642857142857143,
0.5, 0.75, 0.583333333333333, 0.833333333333333, 0.65, 0.5, 0.666666666666667,
0.478260869565217, 0.555555555555556, 1, 0.666666666666667, 0.545454545454545,
0.3125, 0.5, 0.333333333333333, 1, 0.777777777777778, 0.2, 0.375,
0.333333333333333, 0.8, 0.625, 0.666666666666667, 0.555555555555556,
0.666666666666667, 0.857142857142857, 0.5, 0.5, 0.142857142857143,
0.142857142857143, 1, 0.8, 0.571428571428571, 1, 0.428571428571429,
0.5, 0.875, 0.666666666666667, 0.5, 0.833333333333333, 1, 0.333333333333333,
0.7, 0.615384615384615, 0.857142857142857, 0.615384615384615,
0.875, 1, 0.5, 0.916666666666667, 1, 0.6, 0.75, 0.5, 0.666666666666667,
0.866666666666667, 0.6, 0.5, 0.6, 0.96551724137931, 1, 1, 0.625,
0.91304347826087, 1, 1, 0.681818181818182, 0.8, 1), se = c(0.132894358488438,
0.5, 0.163663417676994, 0.148647097502641, 0.0903876907577734,
0.109424330980483, 0.188982236504614, 0.333333333333333, 0.106499554034051,
0.175682092231577, 0, 0.114332390095006, 0.157459164324443, 0.119678388469542,
0.188982236504614, 0.333333333333333, 0, 0.146986183948033, 0.2,
0.18298126367785, 0.333333333333333, 0.133333333333333, 0.18298126367785,
0.333333333333333, 0.175682092231577, 0.333333333333333, 0.142857142857143,
0.121267812518167, 0.288675134594813, 0.142857142857143, 0.142857142857143,
0, 0.2, 0.202030508910442, 0, 0.202030508910442, 0.5, 0.125,
0.333333333333333, 0.288675134594813, 0.166666666666667, 0, 0.333333333333333,
0.152752523165195, 0.140441681411581, 0.142857142857143, 0.140441681411581,
0.125, 0, 0.5, 0.0833333333333333, 0, 0.163299316185545, 0.25,
0.166666666666667, 0.166666666666667, 0.0908513525158996, 0.112390297389803,
0.121267812518167, 0.112390297389803, 0.0344827586206897, 0,
0, 0.18298126367785, 0.0600738504093702, 0, 0, 0.101639453522718,
0.2, 0)), row.names = c(NA, -70L),
groups = structure(list(Confidence = c("55",
"65", "75", "85", "95"),
Type = c("Participants' Calibration",
"Participants' Calibration", "Participants' Calibration", "Participants' Calibration",
"Participants' Calibration"),
.rows = structure(list(1:13, 14:26,
27:41, 42:55, 56:70),
ptype = integer(0),
class = c("vctrs_list_of", "vctrs_vctr", "list"))),
row.names = c(NA, -5L),
class = c("tbl_df", "tbl", "data.frame"),
.drop = TRUE),
class = c("grouped_df", "tbl_df", "tbl", "data.frame"),
na.action = structure(c(`14` = 14L, `19` = 19L, `29` = 29L, `34` = 34L, `46` = 46L, `58` = 58L, `59` = 59L,
`63` = 63L, `79` = 79L), class = "omit"))
And the code for the graphs:
df %>%
group_by(Confidence, Type, Participant) %>%
ggplot(aes(x=Confidence, y= Accuracy, color = Type, group = Type))
geom_line()
geom_errorbar(aes(ymin = Accuracy - se, ymax = Accuracy se), color = "Black", size = .15, width = .2)
geom_point(size = 2)
scale_y_continuous(labels = scales::percent)
labs(y= "YOU ARE RIGHT ___% OF THE TIME.", x = "WHEN YOU ARE ___ % CONFIDENT IN YOUR ANSWER...")
theme_minimal()
facet_wrap(~Participant)
theme(axis.title = element_text(size = 7))
scale_color_brewer(palette = "Set1")
Thanks in advance!
CodePudding user response:
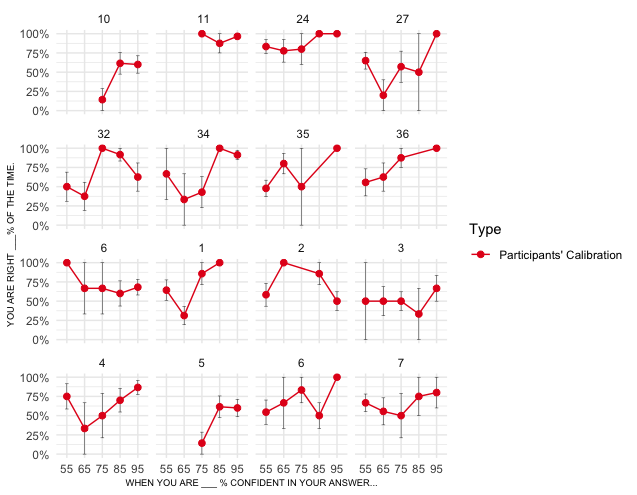
You can add to your plot geom_abline(slope = 1, intercept = 0).
This will only work if your x and y axes are both numeric and on the same scale. Apparently your x values are strings? Let's fix that:
df %>%
mutate(Confidence = as.numeric(Confidence) / 100) %>%
ggplot(aes(x=Confidence, y= Accuracy, color = Type, group = Type))
geom_line()
geom_errorbar(aes(ymin = Accuracy - se, ymax = Accuracy se), color = "Black", size = .15, width = .01)
geom_point(size = 2)
scale_y_continuous(labels = scales::percent_format(accuracy = 1))
scale_x_continuous(labels = scales::percent_format(accuracy = 1))
labs(y= "YOU ARE RIGHT ___% OF THE TIME.", x = "WHEN YOU ARE ___ % CONFIDENT IN YOUR ANSWER...")
theme_minimal()
facet_wrap(~Participant)
theme(axis.title = element_text(size = 7),
panel.grid.minor.x = element_blank())
scale_color_brewer(palette = "Set1")
geom_abline(slope = 1, intercept = 0)