I have a C file. With a C style set of comments /* */ followed by a variable defined for each comment. The variable name is also in the comment. Some comments contain variable names they are not for (see the 3rd comment in the below example)
Here's an example of the format:
/* Object: function1: Does some really cool things and then it ends */
const function1 = someValue;
/* Object: function2: Does more really cool things and then it ends */
const function2 = someValue2;
/* Object: function3: Does even more really cool things
just like function2, does but continues over to the next line for a multiline comment */
const function3 = someValue3;
/* Object: function4: Does all kinds of cool things
and needs function1 in order to set a value correctly */
const function4 = someValue4;
/* Object: function5: Does some other cool things
and needs function2[with another variable] to do some things */
const function5 = someBValue5;
I only want to match the variable names with a result like this: function1 function2 function3 function4 function5
I've been playing around with this on 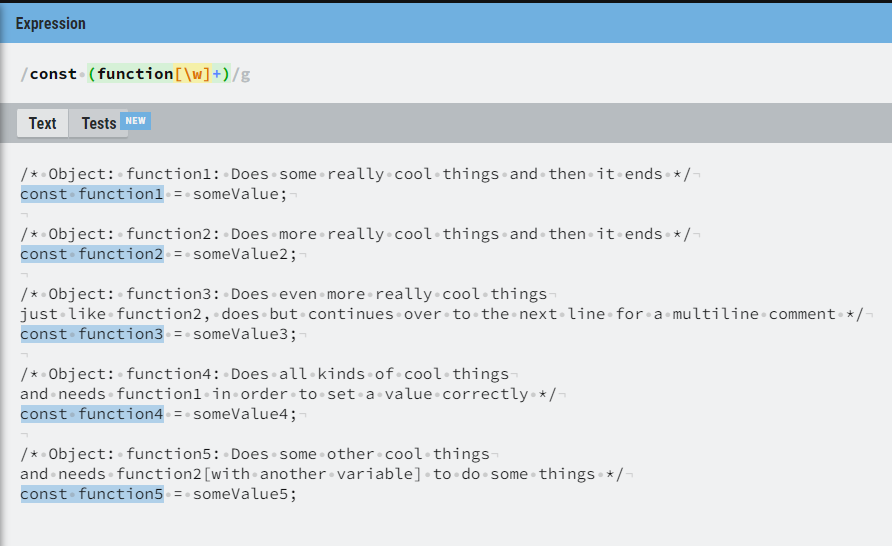
This is not not a complete answer to my problem becuase it doesn't omit the const & space in front of the function name. The function1, function 2 etc are just generic function names. They would be alphanumeric so believe function[\w] still provides the best capture for the function names.
CodePudding user response:
Try using const as a filter:
"const (\bfunction[\w] \b[^:,])"
It won't allow for other neighbours, giving you unique values of function names.
In order to get your group, you need to reference \1 and you'll get only the function name.
CodePudding user response:
My take on the problem: Find a function name from its defintion (so followed by =) outside of comments, but only if it follows a comment where it was mentioned (and followed by :).
Here is a simple, step-by-step state-full approach: Detect whether we are inside a comment, and whether we find /(function[0-9] ):/ and set suitable flags; then look for the same function after the comment.
use warnings;
use strict;
use feature 'say';
my $file = shift // die "Usage: $0 filename\n";
open my $fh, '<', $file or die $!;
my (@func_names, $inside_comment, $func_name);
while (<$fh>) {
chomp;
# Detect whether we are inside a comment, look for function[0-9] : name
if (m{/\*}) { #/ fix syntax hilite
$inside_comment = 1 if not m{\*/}; #/ starts multiline comment?
if (/(function[0-9] ):/) {
$func_name = $1;
}
}
elsif (m{\*/}) { #/ closing line for multiline comment
$inside_comment = 0;
if (not $func_name and /(function[0-9] ):/) { #/
$func_name = $1;
}
}
elsif ($inside_comment and not $func_name) {
if (/(function[0-9] ):/) {
$func_name = $1;
}
}
# Check for name when outside (after) a comment where it was found
elsif (not $inside_comment and $func_name) {
if (/(function[0-9] )\s =/) {
say "Found our definition: $1";
push @func_names, $1;
$func_name = '';
}
}
}
say for @func_names;
This prints as expected with a supplied sample.
A downside: each line is tested twice with a regex. For small files, like source code, one will never notice but it just isn't nice.
There are clearly (edge?) cases which aren't covered,† please test and improve.
† One: If a comment isn't followed by a definition our flags may stay in a faulty state