I am trying to merge to a SQL Database using the following code in Databricks with pyspark
query = """
MERGE INTO deltadf t
USING df s
ON s.SLAId_Id = t.SLAId_Id
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
"""
driver_manager = spark._sc._gateway.jvm.java.sql.DriverManager
con = driver_manager.getConnection(url) #
stmt = con.createStatement()
stmt.executeUpdate(query)
stmt.close()
But I'm getting the following error:
SQLException: Malformed SQL Statement: Expected token 'USING' but found Identifier with value 't' instead at position 25.
Any thoughts on where might be going wrong?
CodePudding user response:
SQLException: Malformed SQL Statement: Expected token 'USING' but found Identifier with value 't' instead at position 25.
if you missed updating any specific field or specific syntax, you will get this error.
I performed 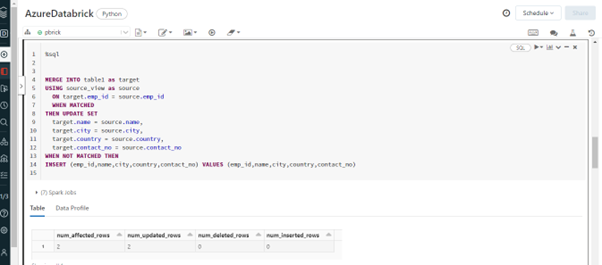
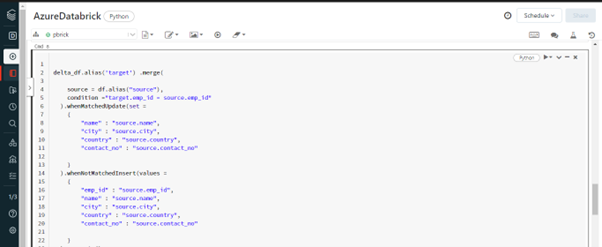
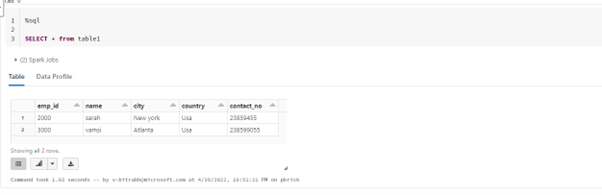
Reference:
https://www.youtube.com/watch?v=i5oM2bUyH0o
https://docs.databricks.com/delta/delta-update.html#upsert-into-a-table-using-merge
https://www.sqlshack.com/sql-server-merge-statement-overview-and-examples/
CodePudding user response:
I don't know why you're getting this exact error. However I believe there are a number of issues with what you are trying to do.
Running the query via JDBC makes it run in SQL Server only. Construct like WHEN MATCHED THEN UPDATE SET * / WHEN NOT MATCHED INSERT * will not work. Databricks accepts it, but for SQL Server you need to explicitly provide columns to update and values to insert (reference).
Also, do you actually have tables named deltadf and df in SQL Server? I suppose you have a Dataframe or temporary view named df... this will not work. As said, this query executes in SQL Server only. If you want to upload data from Dataframe use df.write.format("jdbc").save (reference).
See this Fiddle - if deltadf and df are tables, running this query in SQL Server (any version) will only complain about Incorrect syntax near '*'.