df1 <- data.frame(x1 =
c("b","e","f","g","a","d","c","d","h","d","i","j"), x2 = c("Aug 2017",
"Aug 2017", "Aug 2017","Sep 2017","Sep 2017","Sep 2017","Oct
2017","Oct 2017","Oct 2017","Nov 2017","Nov 2017","Nov 2017"), x3 =
c(456,678,876,987,123,324,345,564,333,255,687,476))
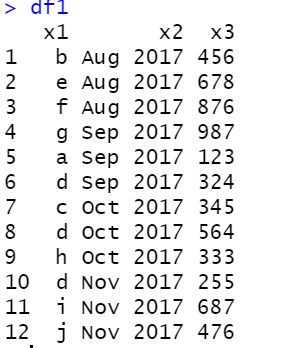
From the above dataframe, I need to find the number of times a value in x1 appears for each time period in x2. In df1, the value 'd' in x1 column occurs 3 times for the months 'Sep 2017', 'Oct 2017,' 'Nov 2017'. I wanna get the value 3 as output. If 'd' occurs for every continuous month in 'x2' column, return the number of times it occurs.
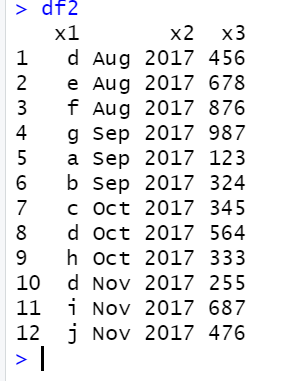
For the data frame df2,'d' occurs in 'Oct 2017', 'Nov 2017' and 'Aug 2017', then the output should be '2' not '3'.
CodePudding user response:
You may try
library(dplyr)
library(zoo)
# Sys.setlocale('LC_ALL','English') # You may run this if df2$x2 prints NA
df2 <- df1 %>%
mutate(x2 = as.yearmon(x2, format = "%b %Y"))
res <- data.frame()
for (i in unique(df2$x1)) {
dummy <- df2[df2$x1 == i,]
m <- ifelse(nrow(dummy) == 1, 1, max(rle(diff(dummy$x2))$lengths) 1)
res <- rbind(res, c(i, m))
}
names(res) <- c("x1", "count")
res
x1 count
1 b 1
2 e 1
3 f 1
4 g 1
5 a 1
6 d 3
7 c 1
8 h 1
9 i 1
10 j 1
CodePudding user response:
You could use zoo::as.yearmon() to convert x2 into a monthly time class, and then diff() to calculate the time differences. (The differnece of two consecutive months is 1/12 in yearmon.) cumsum() is used to dertermine whether a series of times are consecutive or not.
library(dplyr)
df1 %>%
mutate(x2 = zoo::as.yearmon(x2)) %>%
group_by(x1) %>%
arrange(x2, .by_group = TRUE) %>%
summarise(x3 = max(rle(cumsum(c(TRUE, !near(diff(x2), 1/12))))$lengths))
# # A tibble: 10 x 2
# x1 x3
# <chr> <int>
# 1 a 1
# 2 b 1
# 3 c 1
# 4 d 3
# 5 e 1
# 6 f 1
# 7 g 1
# 8 h 1
# 9 i 1
# 10 j 1
Here I use !near(diff(x2), 1/12) instead of diff(x2) != 1/12 because of the roundoff errors.