I have two images from a game and would like to recognize the number on them.
I'm using the newest tesseract version (tesseract v5.2.0.20220708) for windows 10.
So the raw image looks like this:

After processing it with the code below I get this result, which looks pretty good:
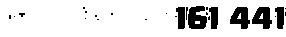
Tesseract recognizes this pretty accurately, but when the number in the image is smaller like in this raw image:

or rather the cleaned version of this

For this image, it doesn't recognize anything and I'm not sure why.
This code I use for cleaning the image
def _prepare_image_for_ocr(img, lower_val, upper_val):
# Create a mask so all non white pixels get "removed"
hsv_image = cv2.cvtColor(img, cv2.COLOR_RGB2HSV)
white_mask = cv2.inRange(hsv_image, lower_val, upper_val)
# Use a little bit of morphology to clean the mask
# Set kernel (structuring element) size
kernel_size = 3
# Set morph operation iterations
op_iterations = 1
# Get the structuring element
morph_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (kernel_size, op_iterations))
# Perform closing and return
return cv2.morphologyEx(white_mask, cv2.MORPH_OPEN,morph_kernel, None, None, op_iterations, cv2.BORDER_REFLECT101)
# Lower and upper val for the first image
lower_val = np.array([30, 30, 30])
upper_val = np.array([255, 255, 255])
# upper val for the second image which needs a bit different values
# upper_val = np.array([230, 230, 230])
# cropped_image is the input RGB image
# Convert to the gray-scale
gry = cv2.cvtColor(cropped_image, cv2.COLOR_RGB2GRAY)
white_mask = _prepare_image_for_ocr(cropped_image, lower_val, upper_val)
# Invert the gray image so we can use it with the mask
inverted_gray = (255 - gry)
# Use the inverted gray image with the white mask to get the white pixels
color_mask = cv2.add(inverted_gray, white_mask)
# blur
blur = cv2.GaussianBlur(color_mask, (0, 0), sigmaX=33, sigmaY=33)
# divide
divide = cv2.divide(color_mask, blur, scale=255)
# Binarize the image
_, binarized_gray = cv2.threshold(divide, 0, 255, cv2.THRESH_OTSU)
cv2.imshow("blur", blur)
cv2.imshow("color_mask", color_mask)
cv2.imshow("divide", divide)
cv2.imshow("binarized_gray", binarized_gray)
cv2.waitKey(1)
# Define custom config for better or
# The digits is a config file that just defines the possible characters as 01233456789
custom_config = r"--psm 8 digits"
cv2.imshow("result image", binarized_gray)
cv2.waitKey(1)
# Do the ocr
result = pytesseract.image_to_string(binarized_gray, lang='eng', config=custom_config)
print(result)
I tried:
- different lower/upper values
- enlarging the image
- using different models, including one specifically for digits
- different psm modes
CodePudding user response:
Better you can go with easyocr.I had tried OCR for the raw images that you given above without any preprocessing.
import easyocr
reader = easyocr.Reader(['en'], gpu=False)
result = reader.readtext('2.png')
for detection in result:
print(detection)
the output for first image is,
([[169, 1], [286, 1], [286, 37], [169, 37]], '161441', 0.744929857940604)
the output for second image is,
([[106, 0], [141, 0], [141, 32], [106, 32]], '91', 0.7728322907607116)
You can install easyocr by pip install easyocr. I hope this will helpful for you.
CodePudding user response:
You can go with keras-ocr then
import matplotlib.pyplot as plt
import keras_ocr
pipeline = keras_ocr.pipeline.Pipeline()
images = [
keras_ocr.tools.read('/content/1.png')
]
prediction_groups = pipeline.recognize(images)
for i, data in enumerate(prediction_groups):
print(data)
the output for first image is
[('161', array([[174., 4.],
[222., 4.],
[222., 34.],
[174., 34.]], dtype=float32)), ('441', array([[231., 5.],
[285., 5.],
[285., 34.],
[231., 34.]], dtype=float32))]
the output for second image is
[('91', array([[109., 3.],
[140., 3.],
[140., 29.],
[109., 29.]], dtype=float32))]
This doesn't cause opencv-python conflicts.