I have a dataframe which contains sales information of products, what i need to do is to create a function which based on the product id, product type and date, calculates the average sales for a time period which is less than the given date in the function.
This is how I have implemented it, but this approach takes a lot of time and I was wondering if there was a faster way to do this. Dataframe:
product_type = ['A','B']
df = pd.DataFrame({'prod_id':np.repeat(np.arange(start=2,stop=5,step=1),235),'prod_type': np.random.choice(np.array(product_type), 705),'sales_time': pd.date_range(start ='1-1-2018',
end ='3-30-2018', freq ='3H'),'sale_amt':np.random.randint(4,100,size = 705)})
Current code:
def cal_avg(product,ptype,pdate):
temp_df = df[(df['prod_id']==product) & (df['prod_type']==ptype) & (df['sales_time']<= pdate)]
return temp_df['sale_amt'].mean()
Calling the function:
cal_avg(2,'A','2018-02-12 15:00:00')
53.983
CodePudding user response:
If you are running the calc_avg function "rarely" then I suggest ignoring my answer. Otherwise, it might be beneficial to you to simply calculate the expanding window average for each product/product type. It might be slow depending on your dataset size (in which case maybe just run it on specific product types?), but you'll only need to run it once. First sort by the column you want to perform the 'expanding' on (expanding is missing the 'on' parameter) to ensure the proper row order. Then 'groupby' and transform each group (to keep the indices of the original dataframe) with your expanding window aggregation of choice (in this case 'mean').
df = df.sort_values('sales_time')
df['exp_mean_sales'] = df.groupby(['prod_id', 'prod_type'])['sale_amt'].transform(lambda gr: gr.expanding().mean())
With the result being:
df.head()
prod_id prod_type sales_time sale_amt exp_mean_sales
0 2 B 2018-01-01 00:00:00 8 8.000000
1 2 B 2018-01-01 03:00:00 72 40.000000
2 2 B 2018-01-01 06:00:00 33 37.666667
3 2 A 2018-01-01 09:00:00 81 81.000000
4 2 B 2018-01-01 12:00:00 83 49.000000
CodePudding user response:
Check Below code, with %%timeit comparison (Google Colab)
import pandas as pd
product_type = ['A','B']
df = pd.DataFrame({'prod_id':np.repeat(np.arange(start=2,stop=5,step=1),235),'prod_type': np.random.choice(np.array(product_type), 705),'sales_time': pd.date_range(start ='1-1-2018',
end ='3-30-2018', freq ='3H'),'sale_amt':np.random.randint(4,100,size = 705)})
## OP's function
def cal_avg(product,ptype,pdate):
temp_df = df[(df['prod_id']==product) & (df['prod_type']==ptype) & (df['sales_time']<= pdate)]
return temp_df['sale_amt'].mean()
## Numpy data prep
prod_id_array = np.array(df.values[:,:1])
prod_type_array = np.array(df.values[:,1:2])
sales_time_array = np.array(df.values[:,2:3], dtype=np.datetime64)
values = np.array(df.values[:,3:])
OP's function -
%%timeit
cal_avg(2,'A','2018-02-12 15:00:00')
Output:

Numpy version
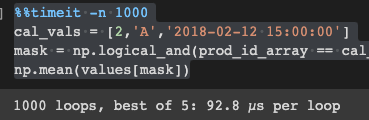
%%timeit -n 1000
cal_vals = [2,'A','2018-02-12 15:00:00']
mask = np.logical_and(prod_id_array == cal_vals[0], prod_type_array == cal_vals[1], sales_time_array <= np.datetime64(cal_vals[2]) )
np.mean(values[mask])
Output: