I have this dataframe.
import pandas as pd
import numpy as np
# data stored in dictionary
details = {
'address_id': [111,111,111,111,111,111,222,222,222,222,222,222,333,333,333,333,333,333,444,444,444,444,444,444,555,555,555,555,555,555,777,777,777,777,777,777,888,888,888,888,888,888],
'my_company':['Comcast','Verizon','Other','Verizon','Comcast','Comcast','Spectrum','Spectrum','Spectrum','Spectrum','Spectrum','Spectrum','Verizon','Verizon','Verizon','Verizon','Verizon','Verizon','Spectrum','Spectrum','Spectrum','Spectrum','Verizon','Spectrum','Spectrum','Spectrum','Spectrum','Spectrum','Verizon','Other','Verizon','Comcast','Comcast','none','none','Verizon','Sprint','Comcast','Comcast','none','none','Verizon'],
'my_date':['2022-01-24','2022-02-21','2022-03-28','2022-04-25','2022-05-23','2022-06-27','2022-01-24','2022-02-21','2022-03-28','2022-04-25','2022-05-23','2022-06-27','2022-01-24','2022-02-21','2022-03-28','2022-04-25','2022-05-23','2022-06-27','2022-01-24','2022-02-21','2022-03-28','2022-04-25','2022-05-23','2022-06-27','2022-01-24','2022-02-21','2022-03-28','2022-04-25','2022-05-23','2022-06-27','2022-01-24','2022-02-21','2022-03-28','2022-04-25','2022-05-23','2022-06-27','2022-01-24','2022-02-21','2022-03-28','2022-04-25','2022-05-23','2022-06-27']
}
df = pd.DataFrame(details)
df
Then I do a simple pivot.
pvt = df.pivot(index='address_id', columns='my_date', values='my_company')
pvt = pvt.reset_index()
This is what I have now.
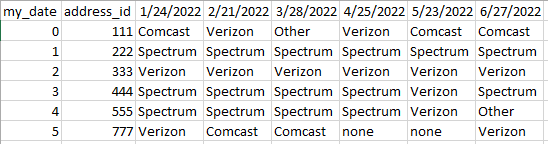
This is what I want to get to.
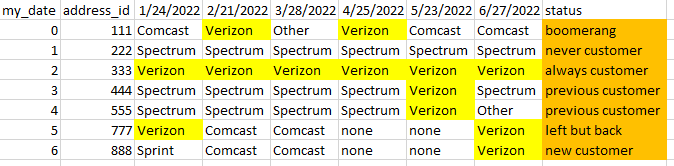
The logic that I'm trying to get to, is this:
#1) was with Verizon then left and then came back and then left = 'boomerang'
#2) was never with Verizon = 'never customer'
#3) was always with Verizon = 'always customer'
#4) was with Verizon at some point, but not with Verizon in the most recent month = 'previous customer'
#5) was with Verizon at some point, then left, but came back to Verizon in the most recent month = 'left but back'
#6) was not with Verizon before the most recent month but just came to Verizon in the most recent month = 'new customer'
I'm thinking it's going to start with something like this...
for column in pvt:
if ('Verizon' not in column):
pvt['status'] = 'never customer'
But, I can tell it's looping through all columns, including the first column, and I don't know how to get this thing to switch back and forth, to find 'boomerang', 'previous customer', 'left but back', and 'new customer'.
If it's very difficult, please tell me. I'm hoping that there is an elegant solution to this problem, but I really don't know.
CodePudding user response:
Just follow your logic with np.select
pvt = df.pivot(index='address_id', columns='my_date', values='my_company')
conda = pvt.iloc[:,-1].eq('Verizon')
condb = pvt.iloc[:,-1].ne('Verizon')
cond1 = pvt.ne('Verizon').all(1)
cond2 = pvt.eq('Verizon').all(1)
cond3 = pvt.eq('Verizon').sum(1)==1
cond4 = pvt.eq('Verizon').sum(1)>1
pvt['new'] = np.select([cond1,cond2,condb&cond3,conda&cond4,conda&cond3],['never','always','pervious','comeback','new'],default = 'boom')