I have a dataframe like this:
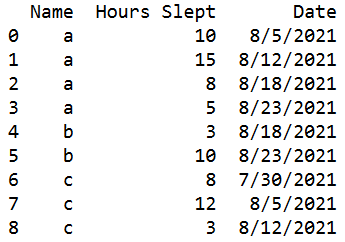
data = [['a', 10, '8/5/2021'], ['a', 15, '8/12/2021'], ['a', 8, '8/18/2021'], ['a', 5, '8/23/2021'], ['b', 3, '8/18/2021'], ['b', 10, '8/23/2021'], ['c', 8, '7/30/2021'], ['c', 12, '8/5/2021'], ['c', 3, '8/12/2021']]
df = pd.DataFrame(data, columns=['Name', 'Hours Slept', 'Date'])
What I'm trying to do is create a new dataframe that shows the name, # of times the person slept 10 hours or more, and the dates that correspond to those times. Something like this:
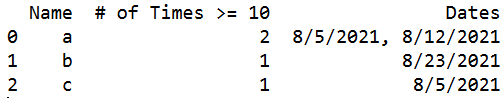
The code should be able to account/ignore NaN and the symbol '*' in the hours slept column.
I know I can do something like this to figure out the # of times the person slept 10 hours or more:
counter = 0
for i in df['Hours Slept']:
if i >= 10:
counter =1
print(counter)
But I can't seem to figure out how to do it in combination with the duplicate Names and how to extract the date.
I cannot select specific Names like using df.loc["a"] because I'll like something that can iterate through all the names (my code has more than a, b, c).
Thank you in advance!
CodePudding user response:
You can use groupby and use aggregation functions:
(
df
.query("`Hours Slept` >= 10")
.groupby("Name", as_index=False)
.agg({"Hours Slept": "size", "Date": ", ".join})
)
Name Hours Slept Date
0 a 2 8/5/2021, 8/12/2021
1 b 1 8/23/2021
2 c 1 8/5/2021
CodePudding user response:
another approach:
df['over10h'] = np.where(df['Hours Slept'].ge(10), 1, 0)
df
Name Hours Slept Date over10h
0 a 10 8/5/2021 1
1 a 15 8/12/2021 1
2 a 8 8/18/2021 0
3 a 5 8/23/2021 0
4 b 3 8/18/2021 0
5 b 10 8/23/2021 1
6 c 8 7/30/2021 0
7 c 12 8/5/2021 1
8 c 3 8/12/2021 0
df1 = df.loc[df['over10h'].ge(1)].groupby(['Name', 'over10h'])['Date'].apply(list).reset_index(name='Dates')
df1["# of times >=10"] = df1['Dates'].map(len)
df1 = df1.drop(columns='over10h')
df1
Name Dates # of times >=10
0 a [8/5/2021, 8/12/2021] 2
1 b [8/23/2021] 1
2 c [8/5/2021] 1