My dataframe:
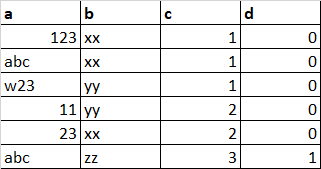
I have to check if the value in each column matches a certain rule. For example:
- If column 'a' has a number, column 'b' has xx or yy, column 'c' has 1 or 2, and column 'd' has 0 -> then the output should be 'output1'
- It is not necessary that all columns should have rules. If a rule does not exist then it should simply ignore it. E.g., for 'output3', it does not matter what is there in column 'c'.
- If it does not match any rules, it should say 'no matches found'.
Since there are so many rules, I created a dictionary of regex rules as follows:
rules_dict =
{'output1': {'a': '^[0-9]*$',
'b': 'xx | yy',
'c': '^[1-2]*$',
'd': '0'},
'output2': {'a': '^[a-z] $',
'b': 'xx | yy',
'c': '1',
'd': '0'},
'output3': {'a': '^[a-zA-Z0-9_.-]*$',
'b': 'xx | yy',
'd': '0'},
'output4': {'a': '^[0-9]*$',
'b': 'xx | yy',
'c': '^[1-2]*$',
'd': '0'}
}
The expected output:
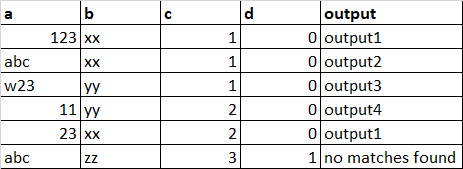
I used the following PySpark script:
for out in rules_dict.keys():
for column, rule in rules_dict[out].items():
output_df = df.withColumn('output', F.when(df[column].rlike(rule), out).otherwise('no matches found'))
output_df.show()
But the output is:
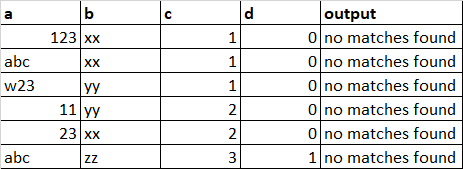
P.S: I am doing it for a large dataset, with a large number of rules. I have only created a sample for simplifying the question.
CodePudding user response:
The thing is, you pass every rule separately to the column. After you pass the first, the second overwrites the first, etc. So, if the first yielded "output1", the second would overwrite it with "no matches found". The third would overwrite both first results and return just "output3" "no matches found". So, effectively you see the result of the 4th rule. And since it has an error, you only get "no matches found".
Input:
from pyspark.sql import functions as F
df = spark.createDataFrame(
[('123', 'xx', '1', '0'),
('abc', 'xx', '1', '0'),
('w23', 'yy', '1', '0'),
( '11', 'yy', '2', '0'),
( '23', 'xx', '2', '0'),
('abc', 'zz', '3', '1')],
['a', 'b', 'c', 'd'])
rules_dict = {
'output1': {'a': '^[0-9]*$',
'b': 'xx|yy',
'c': '^[1-2]*$',
'd': '0'},
'output2': {'a': '^[a-z] $',
'b': 'xx|yy',
'c': '1',
'd': '0'},
'output3': {'a': '^[a-zA-Z0-9_.-]*$',
'b': 'xx|yy',
'd': '0'},
'output4': {'a': '^[0-9]*$',
'b': 'xx|yy',
'c': '^[1-2]*$',
'd': '0'}
}
Script:
conds = F
for out in rules_dict:
ands = F.lit(True)
for c, p in rules_dict[out].items():
ands &= F.col(c).rlike(p)
conds = conds.when(ands, out)
conds = conds.otherwise('no matches found')
df = df.withColumn("output", conds)
df.show()
# --- --- --- --- ----------------
# | a| b| c| d| output|
# --- --- --- --- ----------------
# |123| xx| 1| 0| output1|
# |abc| xx| 1| 0| output2|
# |w23| yy| 1| 0| output3|
# | 11| yy| 2| 0| output1|
# | 23| xx| 2| 0| output1|
# |abc| zz| 3| 1|no matches found|
# --- --- --- --- ----------------
I have fixed your regex patterns, but you still don't get "output4". That's because the first rule also is correct for that line. The first rule comes the first in the when chain, so it returns "output1" and other when conditions are not being evaluated.
CodePudding user response:
@ZygD's answer is very good, but you could also use some for comprehensions and functools so that you don't have to for loop over the config. The other differences are that I am using coalesce to get the first not-null result:
df.withColumn("output", F.coalesce(
*[
F.when(
functools.reduce(lambda x, y: x & y, [F.col(column).rlike(rule) for column, rule in rules_dict[out].items()]),
F.lit(out)
)
for out in rules_dict.keys()
],
F.lit('no matches found')
)).show()