I have a dataframe given below:
df1 = pd.DataFrame({"timestamp": [pd.Timestamp(2016, 7, 29), pd.Timestamp(2017, 8, 22), pd.Timestamp(2017, 10, 9), pd.Timestamp(2018, 1, 9), pd.Timestamp(2018, 3, 31), pd.Timestamp(2018, 7, 5),pd.Timestamp(2018, 8, 5), pd.Timestamp(2018, 9,5), pd.Timestamp(2018, 11, 6),pd.Timestamp(2018, 12, 6), pd.Timestamp(2018, 12, 8)], "userId": [1, 2, 2, 2, 2,2,3, 4, 4, 4,4 ], "movieId": [111065, 35455, 132531, 132531, 2863, 132531, 4493, 133813,8888, 133813,133813], "rating":[3,4,5,2,4,3, 2,2 ,3,1, 3]
})
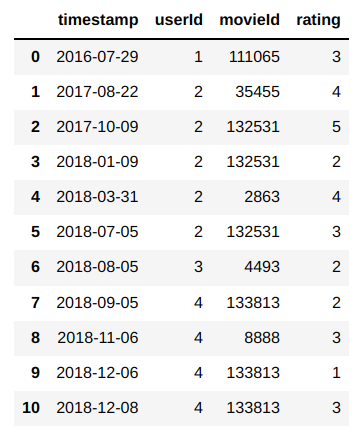
I want to first group by the "userId" column and then for each group remove rows wherever the "movieId" has consecutive duplications. To illustrate better, this is how the end Dataframe should like : (the red rows should be filtered out)
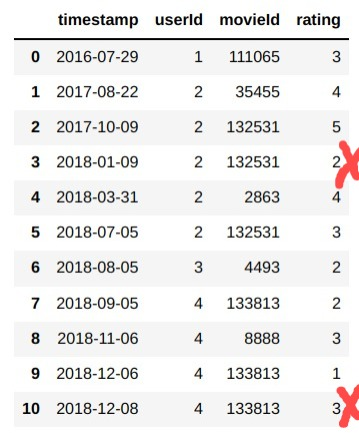
I tried a groupby and filter technique with custom function in lambda, however that doesn't retain all the columns. Please help!
CodePudding user response:
Try .drop_duplicates:
df1 = df1.drop_duplicates(subset=["userId", "movieId"], keep="first")
print(df1)
Prints:
timestamp userId movieId rating
0 2016-07-29 1 111065 3
1 2017-08-22 2 35455 4
2 2017-10-09 2 132531 5
4 2018-03-31 3 4493 4
5 2018-07-05 4 133813 3
CodePudding user response:
Try below code:
import pandas as pd
df1 = pd.DataFrame({"timestamp": [pd.Timestamp(2016, 7, 29), pd.Timestamp(2017, 8, 22), pd.Timestamp(2017, 10, 9), pd.Timestamp(2018, 1, 9), pd.Timestamp(2018, 3, 31), pd.Timestamp(2018, 7, 5),pd.Timestamp(2018, 8, 5), pd.Timestamp(2018, 9,5), pd.Timestamp(2018, 11, 6),pd.Timestamp(2018, 12, 6), pd.Timestamp(2018, 12, 8)], "userId": [1, 2, 2, 2, 2,2,3, 4, 4, 4,4 ], "movieId": [111065, 35455, 132531, 132531, 2863, 132531, 4493, 133813,8888, 133813,133813], "rating":[3,4,5,2,4,3, 2,2 ,3,1, 3]
})
df1['match'] = df1.movieId.eq(df1.movieId.shift())
df1 = df1[df1['match']==False]
print(df1)
Let me know if this helps you