I am writing a simple python program to analyze a data set using linear regression. The program is constructed like so
# Author: Evan Gertis
# Date 11/15
# program: linear regression
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
import logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# read the data from the file
df = pd.read_csv('father_son_data.csv')
logging.info(f"{df}")
# create groups of column names to be plotted together
def chunker(seq, size):
return [seq[pos:pos size] for pos in range(0, len(seq), size)]
# function call
col_list = chunker(df.columns, 2)
# iterate through each group of column names to plot
for x, y in chunker(df.columns, 2):
plot = sns.scatterplot(data=df, x=x, y=y, label=y)
fig = plot.get_figure()
fig.savefig(f"Father_Son.png")
The data is
Height X of father (in), Height Y of son (in)
65, 68
63, 66
67, 68
68, 65
62, 69
70, 68
66, 65
67, 67
67, 68
68, 69
71, 70
What is the best way to plot the line through the points of data? I would like to figure out how to best construct a line through the data using python.
Expected: a straight line through the curve shown in Father_Son.png
Actual: curve shown in Father_Son.png
Thank you in advance!
I made a simple program to plot the data from a csv. I would like to figure out how to best construct a line through the data using python.
CodePudding user response:
Assuming that the csv file has exactly the same format you shown in the question and that the first column represents the independent variable, while the second one is the dependent:
# few libraries
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from scipy import stats
#read the dataset
df = pd.read_csv(FILE_PATH)
#initialize the figure
plt.figure(figsize=FIG_SIZE)
#perform the linear regression
linear_regression = stats.linregress(df)
#scatter the points
plt.scatter(
*df.T.values,
alpha=.5, color=SCATTER_COLOR
)
#define the range of the independent variable as its extreme values in the dataset
x_range = np.array([df.iloc[:,0].min(), df.iloc[:,0].max()])
#define the label shown in the legend
label = """
regression line:
slope = %.{decimals}f ± %.{decimals}f
R = %.{decimals}f (p-value: %.{decimals}e)
""".format(decimals=DECIMALS)%(
linear_regression.slope, #the line slope
linear_regression.stderr, #the line slope standard deviation
linear_regression.rvalue, #the pearson's correlation coefficient
linear_regression.pvalue, #the p-value associated to the pearson's correlation coefficient (Wald test, the null hypothesis is slope=0)
)
#plot the line
plt.plot(
x_range,
linear_regression.intercept x_range*linear_regression.slope, #y=a bx
alpha=.75, color=LINE_COLOR, linestyle=LINE_STYLE,
label=label
)
plt.xlabel(df.columns[0])
plt.ylabel(df.columns[1])
plt.grid(True, linestyle=":", alpha=.5)
plt.legend(loc="best")
plt.savefig(IMG_PATH)
plt.show()
the output in both the IMG_PATH file and the displayed figure is the following:
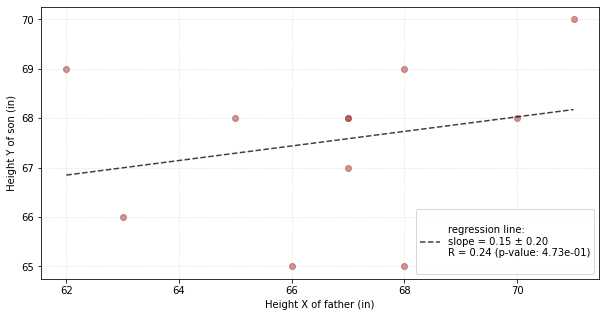
The parameters I have used are the following:
FIG_SIZE = (10,5)
SCATTER_COLOR = "brown"
LINE_COLOR = "black"
LINE_STYLE = "--"
DECIMALS = 2
You also have to assign to FILE_PATH the path of your input csv file and to IMG_PATH the path of your output image file. Note that: the csv extension for the input file is not mandatory since you just need a text comma-separated file (it is important the file is formatted correctly); the format of the output figure file is inferred from the file name (e.g. if IMG_PATH="./img.svg", the image will be formatted in svg).