I have this data in a frequency table. I just want to be able to create a heatmap with Fac1 on Y axis, Fac2 on X axis and the frequency values as heatmap. The order of the Factors in Fac1 and Fac2 must be maintained in the same sequence (after removing duplicates from both Fac1 and Fac2 columns). I haven't been able to get this working after so many tries but I've managed to get the data in order and the simplest representation. I'd greatly appreciate any help in this.
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
import seaborn as sns
url = "https://raw.githubusercontent.com/rroyss/stack/main/dfso.csv"
df = pd.read_csv(url)
plt.subplots(figsize=(15,30))
plt.tick_params(axis='both', which='major', labelsize=10, labelbottom = False, bottom=False, top = True, labeltop=True)
sns.heatmap(df, cmap="Blues", linewidth=1, xticklabels=True, yticklabels=True)
CodePudding user response:
You have to convert your dataframe if you want to sue heatmap:
df['Fac1'] = df['Fac1'].str[5:].map(int)
df['Fac2'] = df['Fac2'].str[6:].map(int)
df2 = df.pivot_table(index='Fac1', columns='Fac2', values='Frequency Fac1-Fac2 pair')
plt.subplots(figsize=(15, 30))
plt.tick_params(axis='both', which='major', labelsize=10, labelbottom=False, bottom=False, top=True, labeltop=True)
sns.heatmap(df2, cmap="Blues", linewidth=1, xticklabels=True, yticklabels=True)
This is the result:
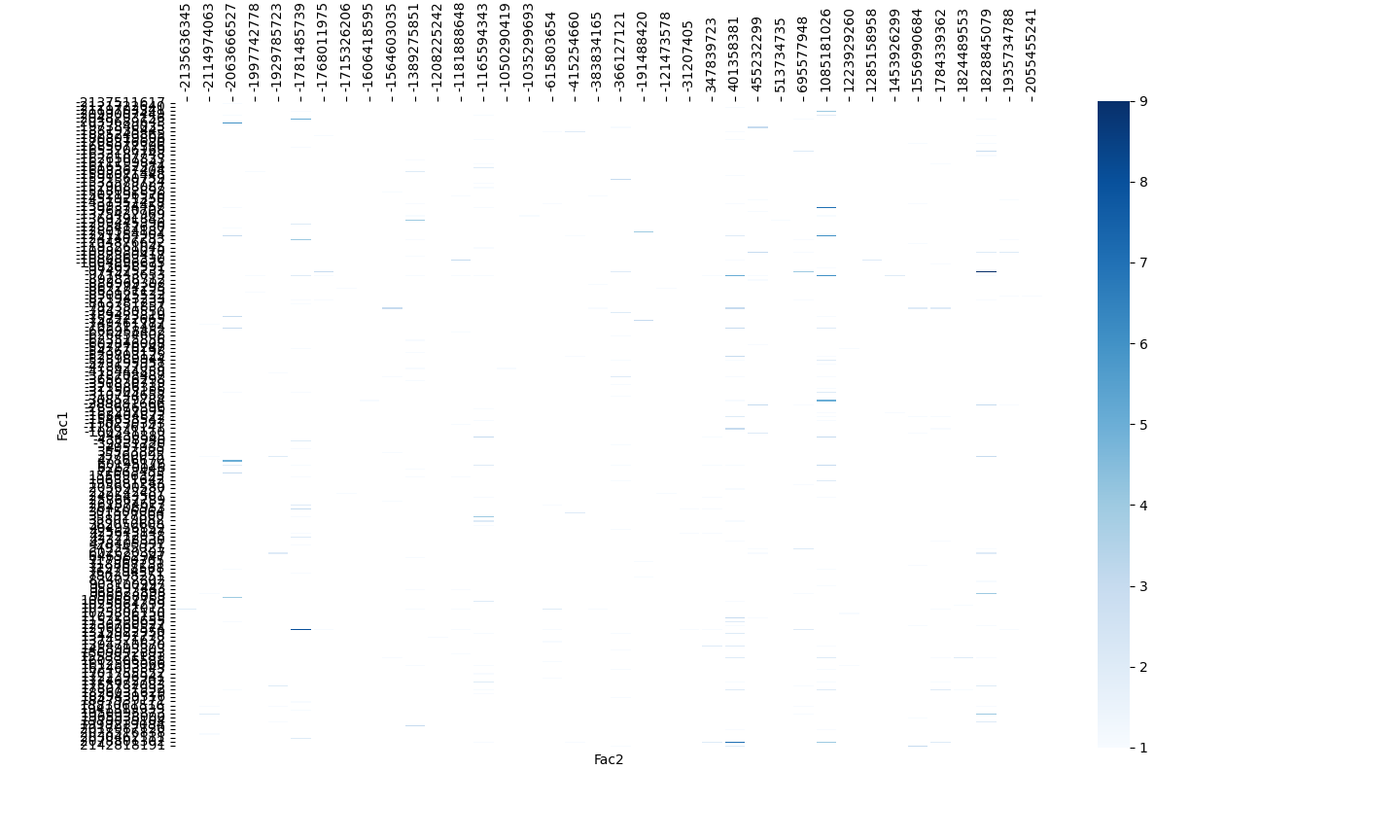
CodePudding user response:
You first need to reorganize the dataframe such that Fac1 becomes the index, Fac2 the columns, and the values are aggregated from the third column. E.g. df_pivoted = df.pivot_table(index='Fac1', columns='Fac2', values='Frequency Fac1-Fac2 pair').
The heatmap will use the order provided by the columns and index as created by pivot_table. Keeping the original order is a bit tricky, but can be achieved by pd.Categorical (which forces an order) combined by pd.unique() (which keeps the original order, unlike np.unique).
from matplotlib import pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
url = "https://raw.githubusercontent.com/rroyss/stack/main/dfso.csv"
df = pd.read_csv(url)
df['Fac1'] = pd.Categorical(df['Fac1'], categories=pd.unique(df['Fac1']))
df['Fac2'] = pd.Categorical(df['Fac2'], categories=pd.unique(df['Fac2']))
df_pivoted = df.pivot_table(index='Fac1', columns='Fac2', values='Frequency Fac1-Fac2 pair')
fig, ax = plt.subplots(figsize=(20, 30))
sns.heatmap(data=df_pivoted, cmap='Blues', xticklabels=True, yticklabels=True, ax=ax)
ax.tick_params(axis='both', which='major', labelsize=10, labeltop=True, top=True, labelbottom=False, bottom=False)
ax.tick_params(axis='x', labelrotation=90)
plt.tight_layout()
plt.show()

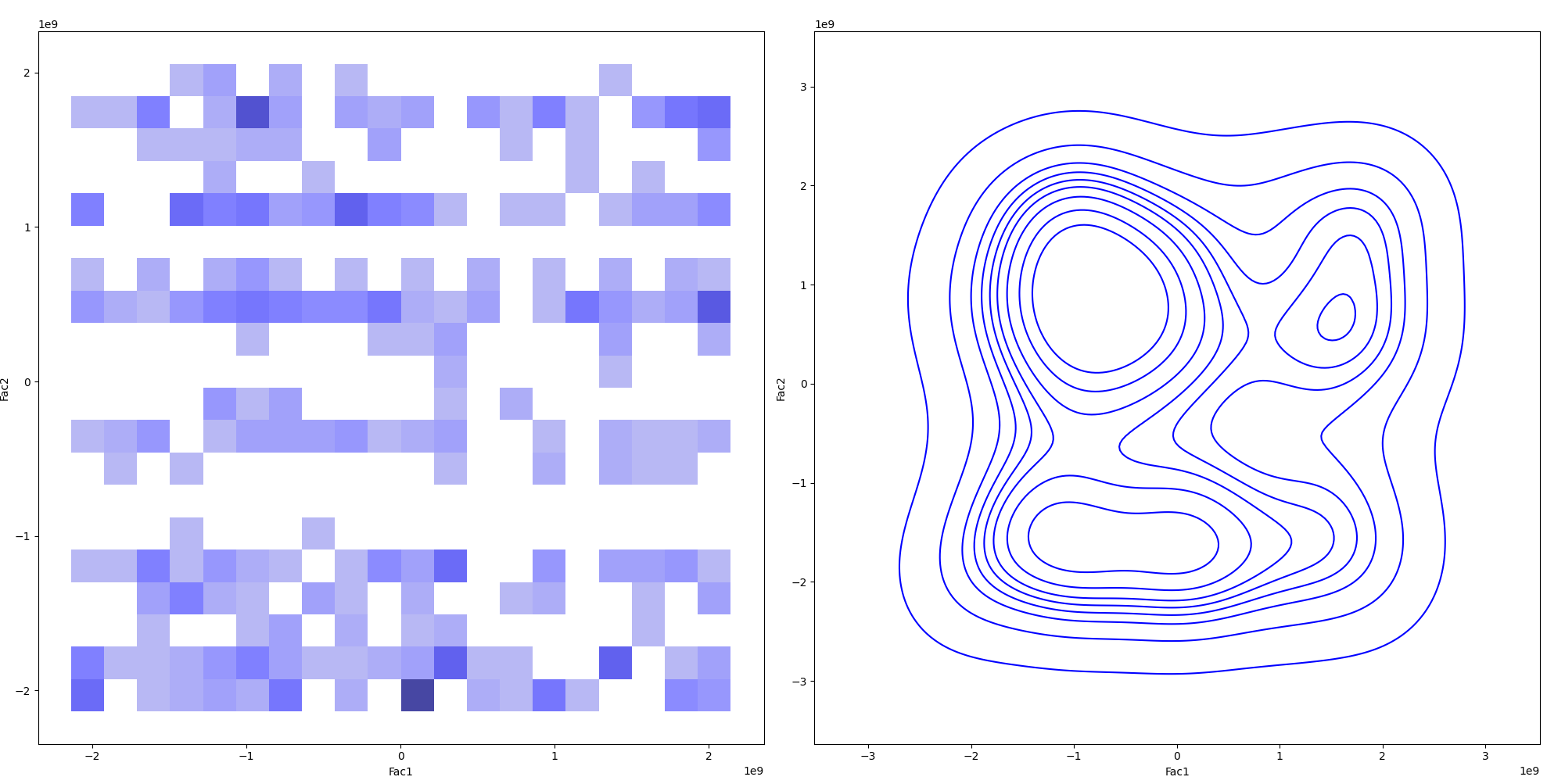
If you are aiming for a 2d histogram or kde plot where the last column is intended as weights:
from matplotlib import pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
url = "https://raw.githubusercontent.com/rroyss/stack/main/dfso.csv"
df = pd.read_csv(url)
df['Fac1'] = [int(f[5:]) for f in df['Fac1']]
df['Fac2'] = [int(f[6:]) for f in df['Fac2']]
fig, (ax1, ax2) = plt.subplots(ncols=2, figsize=(20, 10))
sns.histplot(data=df, x='Fac1', y='Fac2', weights='Frequency Fac1-Fac2 pair', bins=20, color='blue', ax=ax1)
sns.kdeplot(data=df, x='Fac1', y='Fac2', weights='Frequency Fac1-Fac2 pair', color='blue', ax=ax2)
for ax in (ax1, ax2):
ax.tick_params(axis='both', which='major', labelsize=10)
plt.tight_layout()
plt.show()