import pandas as pd
import pyspark.pandas as ps
I am trying to use the pyspark pandas api to compare performance between two similar scripts (one using pandas and one using pyspark through the pandas interface). However, I have trouble importing my data in pyspark from our ADLS Gen 2 storage.
When I run the following code it works as expected:
df_pandas = pd.read_csv(f"az://container/path/to/file.csv",sep=';', dtype=str)
However when I run the same using the pyspark pandas api:
df_spark = ps.read_csv(f"az://container/path/to/file.csv",sep=';', dtype=str)
However, when I run this the following error gets thrown:
Py4JJavaError: An error occurred while calling o1840.load.
: org.apache.hadoop.fs.UnsupportedFileSystemException: No FileSystem for scheme "az"
I have looked online and found others with similar problems using AWS but I'm not sure how to solve it for Azure. I tried replacing az with abfs but I then get the error:
An error occurred while calling o1852.load.
: abfs://container/path/to/file.csv has invalid authority.
I'm running these from Azure Synapse notebooks btw.
CodePudding user response:
I reproduce same in environment.I got this output.
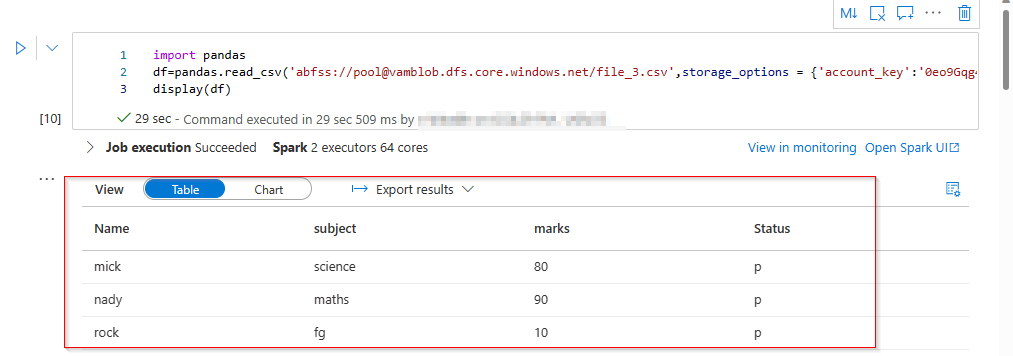
Reading csv files from ADLS Gen2.
Code:
import pandas
df = pandas.read_csv('abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<file_path>', storage_options = {'account_key' : 'account_key_value'})
Output: