

Don't know why, the xpath can only access to the body tag
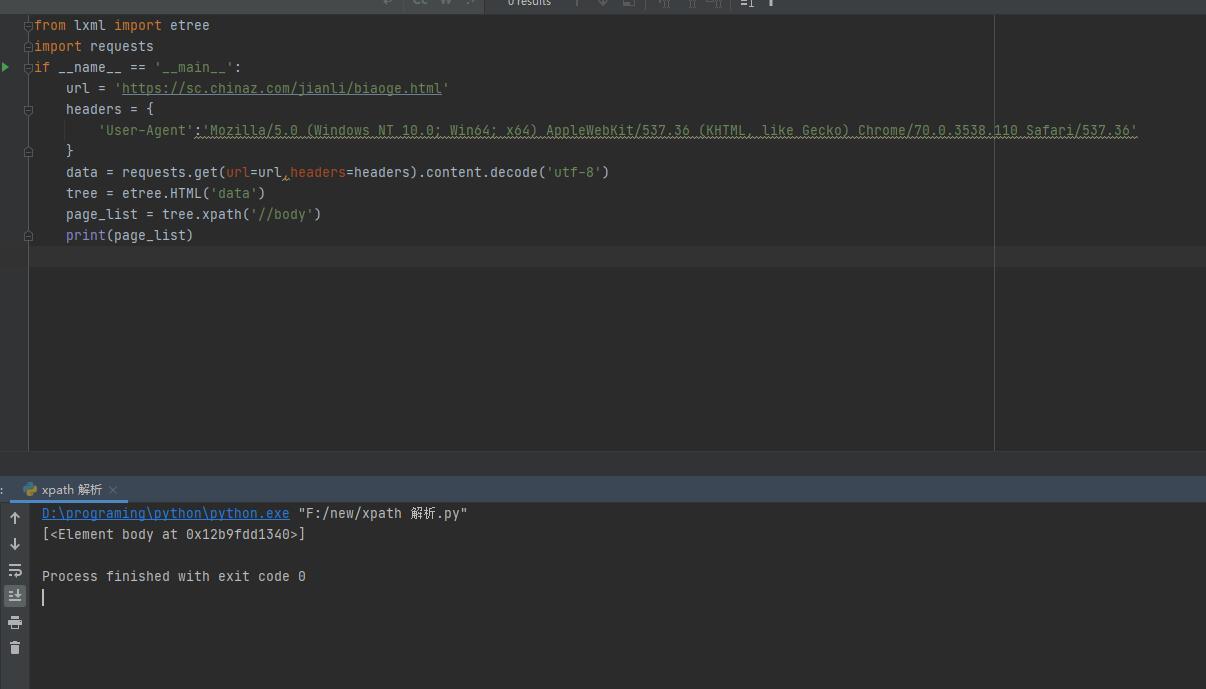
In the body tag parsing path followed by div tags, returned is an empty list
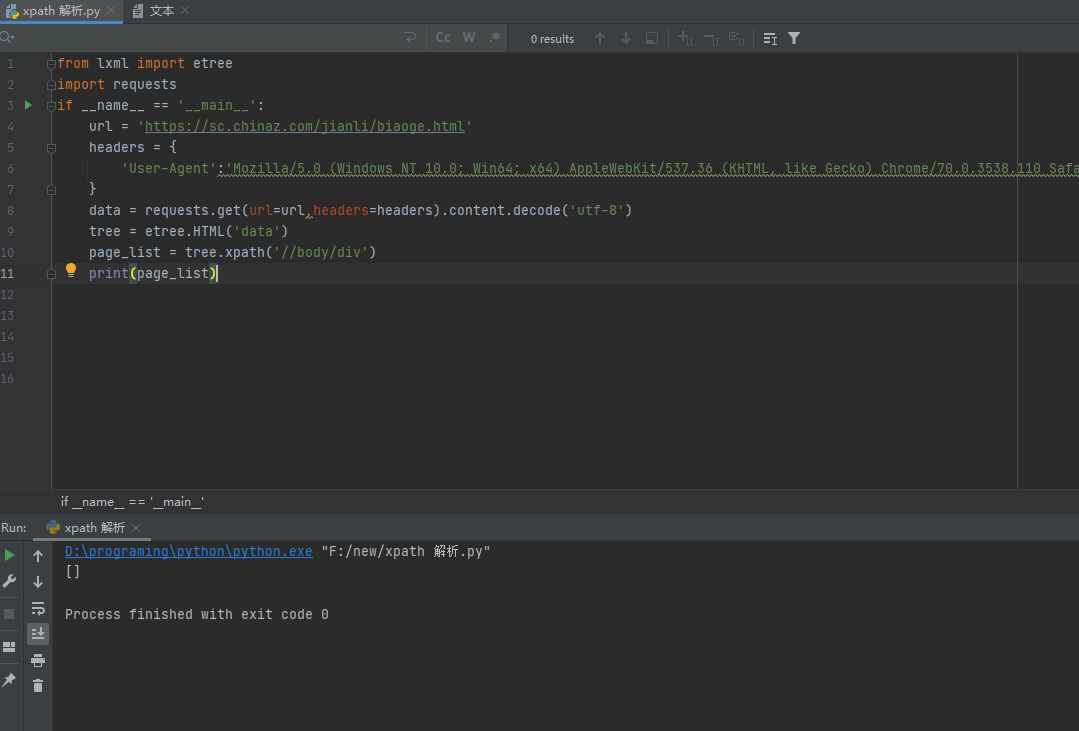
Try to add text behind the body tag () get the text, the returned is an empty list
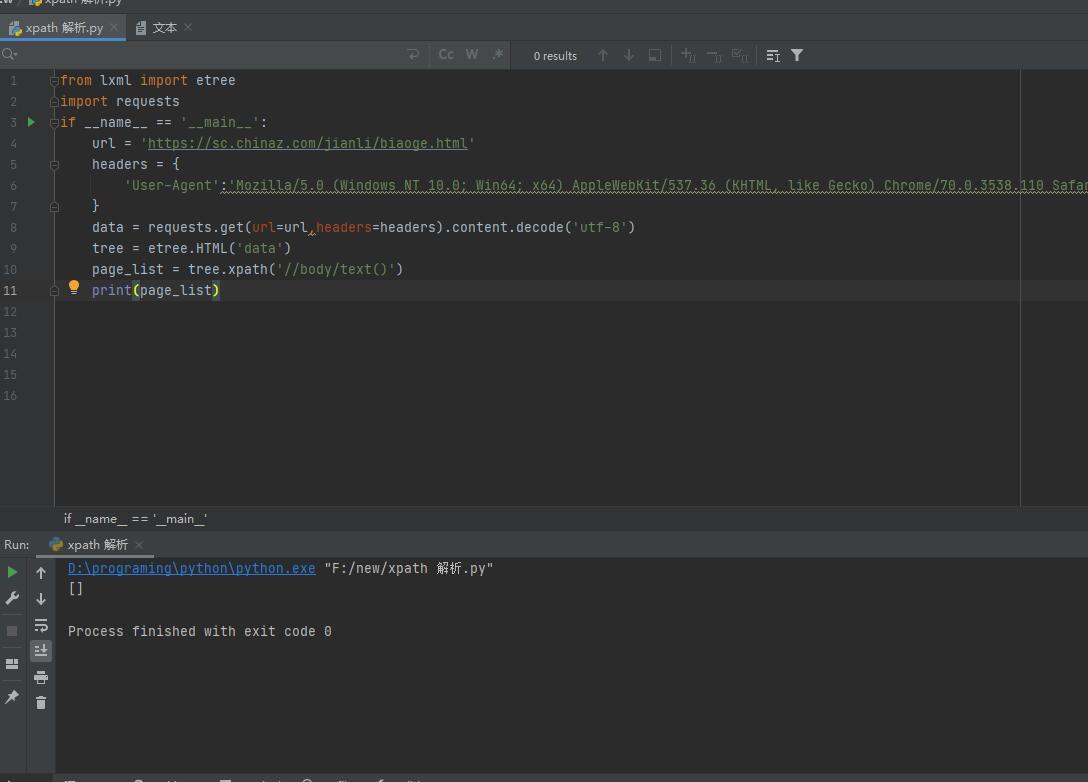
The following is a code
The from LXML import etree
The import requests
If __name__=="__main__ ':
Url='https://sc.chinaz.com/jianli/biaoge.html'
Headers={
'the user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64. X64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36 '
}
Data=https://bbs.csdn.net/topics/requests.get (url=url, headers=headers). The decode (' utf-8)
The tree=etree. HTML (' data ')
Page_list=tree. Xpath ('//body/text () ')
Print (page_list)
CodePudding user response:
No one? [face] monkey2:019 PNG [/face]