I have a dataframe of companies (represented by 'SCU_KEY') that are either customers or just prospects (shown as 'REVENUE_STATUS_FLAG'). Most SCU_KEYs have multiple entries and is updated regularly throughout time. I can't just delete rows that contain 0 in the dataframe, because it's important in my analysis to see moments when it goes from 1 to 0 or if 0 then returns to 1. My best assumption to solve it is through groupby, where if I group the SCU_KEY and the summation REVENUE_STATUS_FLAG is 0, that means that company (SCU_KEY) has only been a prospect and has not had an instance of adopting the product (open to hear alternative ways such as a lambda function for the df/groupby). The code is below and again the goal is to delete rows that contain 0 in the groupby (also containing the image of my returned code) and then make sure those SCU_KEYs are no longer accounted for in the df:
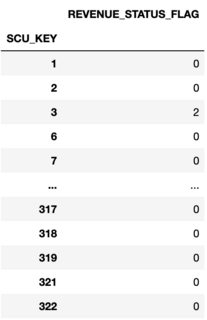
df_4.groupby('SCU_KEY')[['REVENUE_STATUS_FLAG']].sum()
CodePudding user response:
Use transform and a boolean mask to filter your dataframe:
df_4[df_4.groupby('SCU_KEY')['REVENUE_STATUS_FLAG'].transform('sum').gt(0)]
Example:
>>> df_4
SCU_KEY REVENUE_STATUS_FLAG
0 1 0 # drop
1 1 0 # drop
2 1 0 # drop
3 2 0
4 2 1
5 2 0
6 3 0
7 3 0
8 3 2
>>> df_4[df_4.groupby('SCU_KEY')['REVENUE_STATUS_FLAG'].transform('sum').gt(0)]
SCU_KEY REVENUE_STATUS_FLAG
3 2 0
4 2 1
5 2 0
6 3 0
7 3 0
8 3 2
CodePudding user response:
You can also use:
df = pd.DataFrame(data={'scu_key':[1,1,1,2,2,2,3,3,3], 'revenue_status_flag':[0,0,0,1,0,1,1,0,1]})
df = df[df.groupby('scu_key')['revenue_status_flag'].transform(lambda x: ~(x==0).all())]
Input:
scu_key revenue_status_flag
0 1 0
1 1 0
2 1 0
3 2 1
4 2 0
5 2 1
6 3 1
7 3 0
8 3 1
Output:
scu_key revenue_status_flag
3 2 1
4 2 0
5 2 1
6 3 1
7 3 0
8 3 1