I am working with matching two separate dataframes on first name using 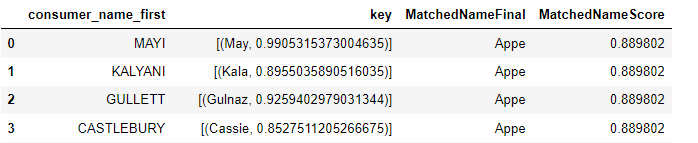
CodePudding user response:
first when going over rows in pandas is better to use apply
matched['MatchedNameFinal'] = matched.key.apply(lambda x: x[0][0])
matched['MatchedNameScore'] = matched.key.apply(lambda x: x[0][1])
and in your case I think you are missing a tab in the for loop
for i, v in enumerate(matched.key):
matched['MatchedNameFinal'] = (matched.key[i][0][0])
matched['MatchedNameScore'] = (matched.key[i][0][1])
CodePudding user response:
Generally, you want to avoid using enumerate for pandas because pandas functions are vectorized and much faster to execute.
So this solution won't iterate using enumerate.
First you turn the list into single tuple per row.
matched.key.explode()
Then use zip to split the tuple into 2 columns.
matched['col1'], matched['col2'] = zip(tuples)
Do all in 1 line.
matched['MatchedNameFinal'], matched['MatchedNameScore'] = zip(*matched.key.explode())