My input:
df1 = pd.DataFrame({'frame':[ 1,1,1,2,3],
'label':['GO','PL','ICV','CL','AO']})
df2 = pd.DataFrame({'frame':[ 1, 1, 2, 3, 4],
'label':['ICV','GO', 'CL','TI','PI']})
df_c = pd.concat([df1,df2])
I trying compare two df, frame by frame, and check if label in df1 existing in same frame in df2. And make some calucation with result (pivot for example)
That my code:
m_df = df1.merge(df2,on=['frame'],how='outer' )
m_df['cross']=m_df.apply(lambda row: 'Matched'
if row['label_x']==row['label_y']
else 'Mismatched', axis='columns')
pv_m = pd.pivot_table(m_df,columns='cross',index='label_x',values='frame', aggfunc=pd.Series.nunique,margins=True, fill_value=0)
but this creates a problem:
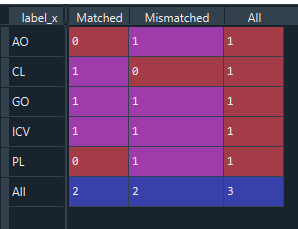
in column All wrong values. as you see GO and ICV I expect in total 2, not 1 as now.
I think maybe there is a smarter way to compare df and pivot them?
CodePudding user response:
You can use isin() function like this:
df3 =df1[df1.label.isin(df2.label)]
CodePudding user response:
You got the unexpected result on margin total because the margin is making use the same function passed to aggfunc (i.e. pd.Series.nunique in this case) for its calculation and the values of Matched and Mismatched in these 2 rows are both the same as 1 (hence only one unique value of 1). (You are currently getting the unique count of frame id's)
Probably, you can achieve more or less what you want by taking the count on them (including margin, Matched and Mismatched) instead of the unique count of frame id's, by using pd.Series.count instead in the last line of codes:
pv_m = pd.pivot_table(m_df,columns='cross',index='label_x',values='frame', aggfunc=pd.Series.count, margins=True, fill_value=0)
Result
cross Matched Mismatched All
label_x
AO 0 1 1
CL 1 0 1
GO 1 1 2
ICV 1 1 2
PL 0 2 2
All 3 5 8