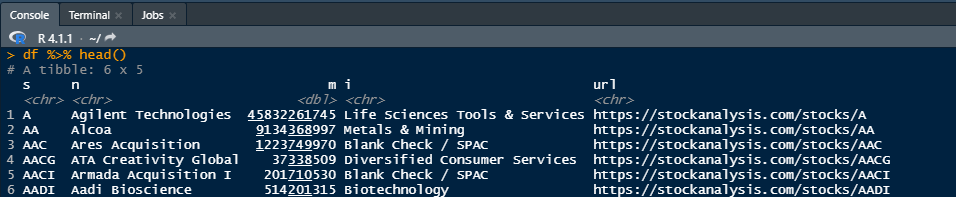
I am trying to read in the table displaying market cap details on 
library(rvest)
library(dplyr)
url <- ("https://stockanalysis.com/stocks/")
page <- read_html(url)
stocks <- page %>%
html_nodes('table#symbol-table') %>%
html_table() %>% .[[1]]
stocks
CodePudding user response:
Observations:
If you scroll down the page you will see there is an option to request more results in a batch. In this particular case, setting to the maximum batch size returns all results in one go.
Monitoring the web traffic shows no additional traffic when requesting more results meaning the data is present in the original response.
Doing a search of the page source for the last symbol reveals the all the items are pre-loaded in a script tag. Examining the JavaScript source files shows the instructions for pushing new batches onto the page based on various input params.
Solution:
You can simply extract the JavaScript object from the script tag and parse as JSON. Convert the list of lists to a dataframe then add in a constructed url based on common base string symbol.
TODO:
- Up to you if you wish to update header names
- You may wish to format the numeric column to match webpage format
R:
library(rvest)
library(jsonlite)
library(tidyverse)
r <- read_html('https://stockanalysis.com/stocks/') %>%
html_element('#__NEXT_DATA__') %>%
html_text() %>%
jsonlite::parse_json()
df <- map_df(r$props$pageProps$stocks, ~ .x)%>%
mutate(url = paste0('https://stockanalysis.com/stocks/', s))
Sample output: