I have a large dataframe with users scores on a number of language dimensions, with a simplified version looking like the code below (I have included a dput replication data at the bottom of the post)
user Authentic Analytic Clout Tone
2 Adams_Alma 0.05738848 0.7511374 0.3675847 0.95387755
3 Aguilar_Pete 0.24302974 0.7725205 0.3873588 0.79183673
4 Allred_Colin 0.11245353 0.7770701 0.7482345 0.58346939
5 Auchincloss_Jake 0.96119888 0.8020928 0.2673023 0.49765306
6 Axne_Cynthia 0.12500000 0.8644222 0.4918785 0.97112245
Using this data, I want to create a dataframe in which each row is the difference score of between a pair of users in the dataset, as seen below (though the actual dataframe is much larger).
from to diff_Authentic diff_Analytic diff_Clout diff_Tone
1 Adams_Alma Aguilar_Pete 0.9802260 0.123456 0.123456 0.123456
2 Adams_Alma Allred_Colin 0.6193503 0.123456 0.123456 0.123456
3 Adams_Alma Auchincloss_Jake 0.8997175 0.123456 0.123456 0.123456
4 Adams_Alma Axne_Cynthia 0.8757062 0.123456 0.123456 0.123456
5 Adams_Alma Baldwin_Tammy 0.9406780 0.123456 0.123456 0.123456
6 Adams_Alma Barragán_Nanette 0.8495763 0.123456 0.123456 0.123456
7 Adams_Alma Bass_Karen 0.8234463 0.123456 0.123456 0.123456
8 Adams_Alma Beatty_Joyce 0.9014831 0.123456 0.123456 0.123456
9 Adams_Alma Bennet_Michael 0.5183616 0.123456 0.123456 0.123456
10 Adams_Alma Bera_Ami 0.8223870 0.123456 0.123456 0.123456
Using the code below, I am able to create a difference edgelist for one variable at a time, but my full dataframe has 90 variables I want differences for.
out <- with(norm_data, as.matrix(dist(setNames(norm_data$Authentic, norm_data$user))))
dif_g <- graph_from_adjacency_matrix (out, mode = 'undirected', weighted = TRUE)
dif_edge_list <- as_data_frame(dif_g, 'edges')
dif_edge_list$weight <- 1 - dif_edge_list$weight
I would like to have a single dataframe that has the difference scores for each pair of users across all variables. I'm assuming a loop might be the solution, but I can't figure out how to do this. Any help would be greatly appreciated. Let me know if you need any more info.
Dput Data:
Show in New WindowClear OutputExpand/Collapse Output
structure(list(user = structure(1:50, .Label = c("Adams_Alma",
"Aguilar_Pete", "Allred_Colin", "Auchincloss_Jake", "Axne_Cynthia",
"Baldwin_Tammy", "Barragán_Nanette", "Bass_Karen", "Beatty_Joyce",
"Bennet_Michael", "Bera_Ami", "Beyer_Donald", "Bishop_Sanford",
"Blumenthal_Richard", "Blunt_Rochester_Lisa", "Bonamici_Suzanne",
"Booker_Cory", "Bourdeaux_Carolyn", "Bowman_Jamaal", "Boyle_Brendan",
"Brown_Anthony", "Brown_Sherrod", "Brownley_Julia", "Bush_Cori",
"Bustos_Cheri", "Butterfield_George", "Cantwell_Maria", "Carbajal_Salud",
"Cárdenas_Tony", "Cardin_Benjamin", "Carper_Thomas", "Carson_André",
"Cartwright_Matthew", "Case_Ed", "Casey_Robert", "Casten_Sean",
"Castor_Kathy", "Castro_Joaquin", "Chu_Judy", "Cicilline_David",
"Clark_Katherine", "Clarke_Yvette", "Cleaver_Emanuel", "Clyburn_James",
"Cohen_Steve", "Connolly_Gerald", "Coons_Christopher", "Cooper_Jim",
"Correa_J", "Cortez_Masto_Catherine", "Costa_Jim", "Courtney_Joe",
"Craig_Angie", "Crist_Charlie", "Crow_Jason", "Cuellar_Henry",
"Davids_Sharice", "Davis_Danny", "Dean_Madeleine", "DeFazio_Peter",
"DeGette_Diana", "DeLauro_Rosa", "DelBene_Suzan", "Delgado_Antonio",
"Demings_Val", "DeSaulnier_Mark", "Deutch_Theodore", "Dingell_Debbie",
"Doggett_Lloyd", "Doyle_Michael", "Duckworth_Tammy", "Durbin_Richard",
"Escobar_Veronica", "Eshoo_Anna", "Espaillat_Adriano", "Evans_Dwight",
"Feinstein_Dianne", "Fletcher_Lizzie", "Foster_Bill", "Frankel_Lois",
"Gallego_Ruben", "Garamendi_John", "García_Jesús", "Garcia_Sylvia",
"Golden_Jared", "Gomez_Jimmy", "Gonzalez_Vicente", "Gottheimer_Josh",
"Green_Al", "Grijalva_Raúl", "Harder_Josh", "Hassan_Margaret",
"Hayes_Jahana", "Heinrich_Martin", "Higgins_Brian", "Himes_James",
"Hirono_Mazie", "Horsford_Steven", "Houlahan_Chrissy", "Hoyer_Steny",
"Huffman_Jared", "Jackson_Lee_Sheila", "Jacobs_Sara", "Jayapal_Pramila",
"Jeffries_Hakeem", "Johnson_Eddie", "Johnson_Henry", "Kaptur_Marcy",
"Keating_William", "Kelly_Mark", "Kelly_Robin", "Khanna_Ro",
"Kildee_Daniel", "Kilmer_Derek", "Kim_Andy", "Kind_Ron", "Kirkpatrick_Ann",
"Klobuchar_Amy", "Krishnamoorthi_Raja", "Kuster_Ann", "Lamb_Conor",
"Langevin_James", "Larsen_Rick", "Larson_John", "Lawrence_Brenda",
"Lawson_Al", "Leahy_Patrick", "Lee_Barbara", "Lee_Susie", "Leger_Fernandez_Teresa",
"Levin_Andy", "Levin_Mike", "Lieu_Ted", "Lofgren_Zoe", "Lowenthal_Alan",
"Luján_Ben", "Luria_Elaine", "Lynch_Stephen", "Malinowski_Tom",
"Maloney_Carolyn", "Maloney_Sean", "Manchin_Joe", "Manning_Kathy",
"Markey_Edward", "Matsui_Doris", "McBath_Lucy", "McCollum_Betty",
"McEachin_A", "McGovern_James", "McNerney_Jerry", "Meeks_Gregory",
"Menendez_Robert", "Meng_Grace", "Merkley_Jeff", "Mfume_Kweisi",
"Moore_Gwen", "Morelle_Joseph", "Moulton_Seth", "Mrvan_Frank",
"Murphy_Stephanie", "Murray_Patty", "Nadler_Jerrold", "Napolitano_Grace",
"Neal_Richard", "Neguse_Joe", "Newman_Marie", "Norcross_Donald",
"Norton_Eleanor", "O_Halleran_Tom", "Ocasio_Cortez_Alexandria",
"Omar_Ilhan", "Ossoff_Jon", "Padilla_Alejandro", "Pallone_Frank",
"Panetta_Jimmy", "Pappas_Chris", "Pascrell_Bill", "Payne_Donald",
"Pelosi_Nancy", "Perlmutter_Ed", "Peters_Gary", "Peters_Scott",
"Phillips_Dean", "Pingree_Chellie", "Plaskett_Stacey", "Pocan_Mark",
"Porter_Katie", "Pressley_Ayanna", "Price_David", "Quigley_Mike",
"Raskin_Jamie", "Reed_John", "Rice_Kathleen", "Rosen_Jacky",
"Ross_Deborah", "Roybal_Allard_Lucille", "Ruiz_Raul", "Ruppersberger_C",
"Rush_Bobby", "Ryan_Tim", "Sablan_Gregorio", "Sánchez_Linda",
"Sarbanes_John", "Scanlon_Mary", "Schakowsky_Janice", "Schatz_Brian",
"Schiff_Adam", "Schneider_Bradley", "Schrader_Kurt", "Schrier_Kim",
"Schumer_Charles", "Scott_David", "Scott_Robert", "Sewell_Terri",
"Shaheen_Jeanne", "Shelby_Richard", "Sherman_Brad", "Sherrill_Mikie",
"Sinema_Kyrsten", "Sires_Albio", "Slotkin_Elissa", "Smith_Adam",
"Smith_Tina", "Soto_Darren", "Spanberger_Abigail", "Speier_Jackie",
"Stabenow_Debbie", "Stanton_Greg", "Stevens_Haley", "Strickland_Marilyn",
"Suozzi_Thomas", "Swalwell_Eric", "Takano_Mark", "Tester_Jon",
"Thompson_Bennie", "Thompson_Mike", "Titus_Dina", "Tlaib_Rashida",
"Tonko_Paul", "Torres_Norma", "Torres_Ritchie", "Trahan_Lori",
"Trone_David", "Underwood_Lauren", "user", "Van_Hollen_Chris",
"Vargas_Juan", "Veasey_Marc", "Vela_Filemon", "Velázquez_Nydia",
"Warner_Mark", "Warnock_Raphael", "Warren_Elizabeth", "Wasserman_Schultz_Debbie",
"Waters_Maxine", "Watson_Coleman_Bonnie", "Welch_Peter", "Wexton_Jennifer",
"Whitehouse_Sheldon", "Wild_Susan", "Williams_Nikema", "Wilson_Frederica",
"Wyden_Ron", "Yarmuth_John"), class = "factor"), Authentic = c(0.0573884758364312,
0.243029739776952, 0.112453531598513, 0.961198884758364, 0.125,
0.139869888475836, 0.131737918215613, 0.174024163568773, 0.115706319702602,
0.325046468401487, 0.223048327137546, 0.087592936802974, 0.133364312267658,
0.190985130111524, 0.21003717472119, 0.0422862453531598, 0.153113382899628,
0.263708178438662, 0.157295539033457, 0.328996282527881, 0.139637546468401,
0.48025092936803, 0.26974907063197, 0.378020446096654, 0.153113382899628,
0.454693308550186, 0.0820167286245353, 0.130576208178439, 0.33317843866171,
0.263243494423792, 0.197490706319703, 0.295074349442379, 0.251626394052045,
0.303671003717472, 0.180065055762082, 0.155204460966543, 0.10246282527881,
0.237453531598513, 0.132434944237918, 0.151022304832714, 0.10339219330855,
0.991635687732342, 0.185176579925651, 0.263475836431227, 0.0669144981412639,
0.143587360594796, 0.127788104089219, 0.212360594795539, 0.45817843866171,
0.054135687732342), Analytic = c(0.751137397634213, 0.772520473157416,
0.777070063694267, 0.802092811646951, 0.86442220200182, 0.75796178343949,
0.847133757961783, 0.873976342129208, 0.816196542311192, 0.801182893539581,
0.809827115559599, 0.695177434030937, 0.803457688808007, 0.726569608735214,
0.774795268425842, 0.843039126478617, 0.788898999090082, 0.773885350318471,
0.79936305732484, 0.78434940855323, 0.939945404913557, 0.772520473157416,
0.741128298453139, 0.736123748862602, 0.927206551410373, 0.673794358507734,
0.859872611464968, 0.763421292083712, 0.810282074613285, 0.871701546860782,
0.834849863512284, 0.786624203821656, 0.782984531392174, 1, 0.872611464968152,
0.748862602365787, 0.804367606915377, 0.79936305732484, 0.682893539581438,
0.761601455868971, 0.722929936305732, 0.767970882620564, 0.845313921747043,
0.79663330300273, 0.74294813466788, 0.840764331210191, 0.894904458598726,
0.787534121929026, 0.800272975432211, 0.883530482256597), Clout = c(0.367584745762712,
0.387358757062147, 0.748234463276836, 0.267302259887006, 0.491878531073446,
0.426906779661017, 0.518008474576271, 0.191031073446328, 0.466101694915254,
0.849223163841808, 0.545197740112994, 0.475988700564972, 0.548728813559322,
0.711511299435028, 0.538841807909604, 0.792372881355932, 0.49364406779661,
0.487641242937853, 0.64795197740113, 0.370409604519774, 0.771186440677966,
0.288488700564972, 0.211158192090395, 0.273658192090395, 0.420197740112994,
1, 0.531779661016949, 0.629237288135593, 0.646539548022599, 0.208686440677966,
0.189618644067797, 0.92090395480226, 0.632415254237288, 0.965042372881356,
0.34180790960452, 0.392302259887005, 0.604166666666666, 0.548375706214689,
0.401836158192091, 0.415254237288136, 0.364759887005649, 0.332980225988701,
0.354519774011299, 0.346398305084746, 0.52295197740113, 0.453389830508474,
0.777189265536723, 0.332980225988701, 0.436087570621469, 0.387358757062147
), Tone = c(0.953877551020408, 0.791836734693877, 0.583469387755102,
0.49765306122449, 0.971122448979592, 0.994183673469388, 0.626836734693878,
0.893061224489796, 0.34469387755102, 0.68530612244898, 0.970204081632653,
0.698265306122449, 0.959795918367347, 0.379183673469388, 0.988469387755102,
0.930408163265306, 0.0593877551020408, 0.744897959183674, 0.884387755102041,
0.803367346938776, 0.659285714285714, 0.422244897959184, 0.283571428571429,
0.252755102040816, 0.926530612244898, 0.988265306122449, 0.76469387755102,
0.525408163265306, 0.817040816326531, 0.891428571428571, 0.81265306122449,
0.451632653061224, 0.654285714285714, 0.727244897959184, 0.974591836734694,
0.467448979591837, 0.798775510204082, 0.501122448979592, 0.919795918367347,
0.744897959183674, 0.83234693877551, 0.931224489795918, 0.866326530612245,
0.448673469387755, 0.766530612244898, 0.326734693877551, 0.847959183673469,
0.685204081632653, 0.78765306122449, 0.847755102040816)), row.names = 2:51, class = "data.frame")
CodePudding user response:
In order to avoid repetition and thus not using O(N^2), i would prefer using vectorized methods. We know that we need 1-2,1-3.. etc and these are the same as 2-1,3-1, upto the sign constant. We could do:
index <- which(lower.tri(diag(nrow(df))), T)
a <- data.frame(user1 = df[index[,2],1],
user2 = df[index[,1],1],
diff = df[index[,2],-1] - df[index[,1],-1], row.names = NULL)
user1 user2 diff.Authentic diff.Analytic diff.Clout diff.Tone
1 Adams_Alma Aguilar_Pete -0.18564126 -0.021383076 -0.01977401 0.16204082
2 Adams_Alma Allred_Colin -0.05506506 -0.025932666 -0.38064972 0.37040816
3 Adams_Alma Auchincloss_Jake -0.90381041 -0.050955414 0.10028249 0.45622449
4 Adams_Alma Axne_Cynthia -0.06761152 -0.113284804 -0.12429379 -0.01724490
5 Adams_Alma Baldwin_Tammy -0.08248141 -0.006824386 -0.05932203 -0.04030612
6 Adams_Alma Barragán_Nanette -0.07434944 -0.095996360 -0.15042373 0.32704082
CodePudding user response:
Here is a solution:
library(tidyverse)
crossing(data, user2 = data$user) %>%
filter(user != user2) %>%
left_join(data, by = c("user2" = "user")) %>%
transmute(
from = user,
to = user2,
Authentic_diff = Authentic.y - Authentic.x,
Analytic_diff = Analytic.y - Analytic.x,
Clout_diff = Clout.y - Clout.x,
Tone_diff = Tone.y - Tone.x
)
CodePudding user response:
# set as data.table
setDT(df)
# as.character (needed to rid permutation)
df[, user := as.character(user)]
# cross join
df_1 <- df[, as.list(df), names(df)]
# name change
x <- unlist(lapply(list('x.', 'i.'), \(i) paste0(i, names(df))))
names(df_1) <- x
# rid combo from replacement. Change to != for permutation
df_1 <- df_1[i.user < x.user]
# names net prefix
y <- gsub('x\\.|i\\.', '', x)
# construct formula
z <- lapply(2:5, \(i) paste0('diff_', y[i], '=', x[i], '-', x[i 5]))
a <- paste('.(' ,paste(unlist(z), collapse=','), ')')
# calculate diff
df_1[, eval(parse(text=a))]
and my personal fav. Benchmarking :)
# benchmark
library(microbenchmark)
xx <-
microbenchmark(sweepydodo = {# set as data.table
setDT(df)
# as.character (needed to rid permutation)
df[, user := as.character(user)]
# cross join
df_1 <- df[, as.list(df), names(df)]
# name change
x <- unlist(lapply(list('x.', 'i.'), \(i) paste0(i, names(df))))
names(df_1) <- x
# rid combo from replacement. Change to != for permutation
df_1 <- df_1[i.user < x.user]
# names net prefix
y <- gsub('x\\.|i\\.', '', x)
# construct formula
z <- lapply(2:5, \(i) paste0('diff_', y[i], '=', x[i], '-', x[i 5]))
a <- paste('.(' ,paste(unlist(z), collapse=','), ')')
# calculate diff
df_1[, eval(parse(text=a))]
}
, Onyambu = {index <- which(lower.tri(diag(nrow(df))), T)
a <- data.frame(user1 = df[index[,2],1],
user2 = df[index[,1],1],
diff = df[index[,2],-1] - df[index[,1],-1]
, row.names = NULL
)
}
, Iman = {crossing(df, user2 = df$user) %>%
filter(user != user2) %>%
left_join(df, by = c("user2" = "user")) %>%
transmute(
from = user,
to = user2,
Authentic_diff = Authentic.y - Authentic.x,
Analytic_diff = Analytic.y - Analytic.x,
Clout_diff = Clout.y - Clout.x,
Tone_diff = Tone.y - Tone.x
)
}
, times = 30
)
# plot
autoplot(xx)
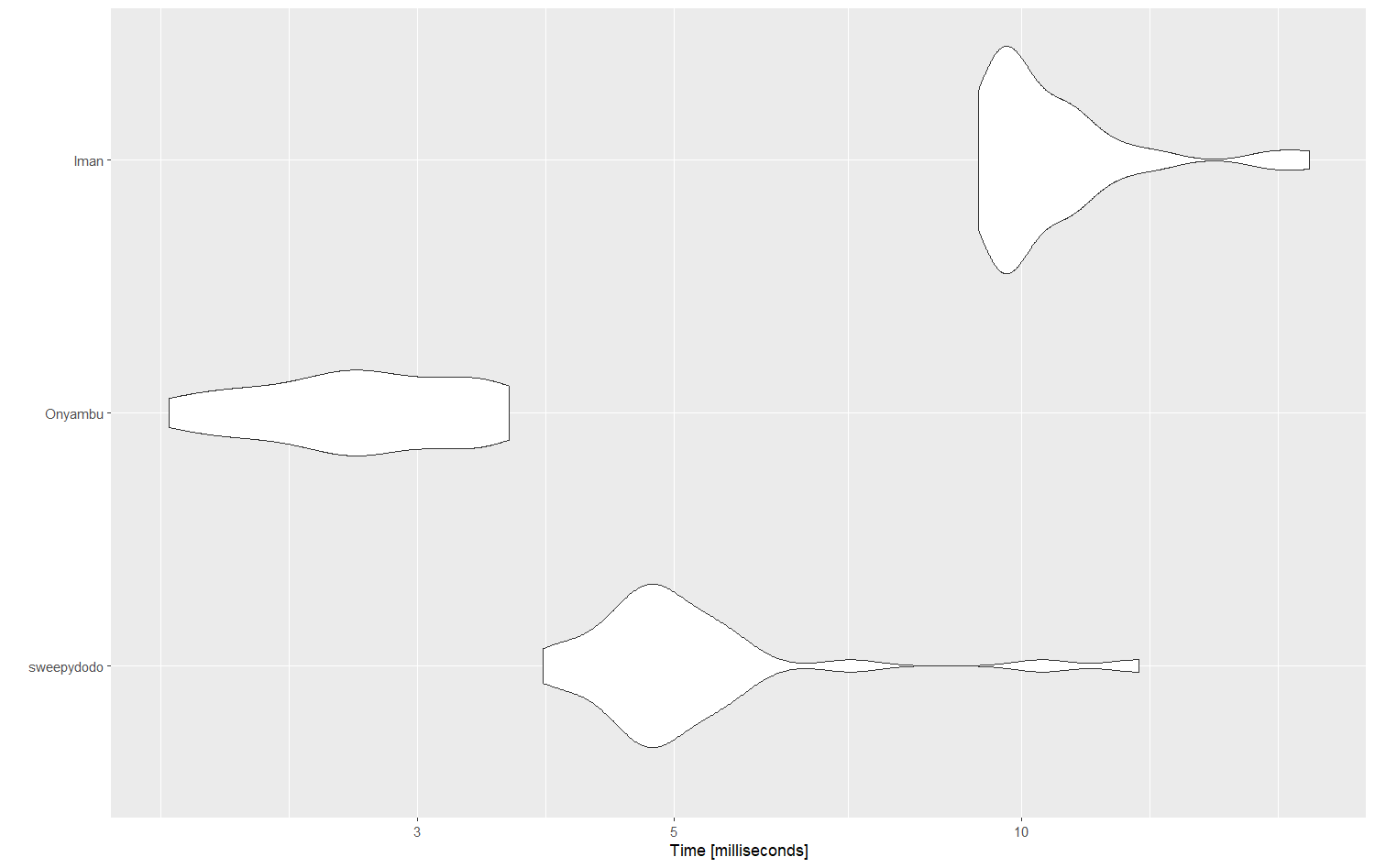
@Onyambu 's solution does run faster! The benefits of not using joins