I am new to using LSI with Python and Gensim Scikit-learn tools. I was able to achieve topic modeling on a corpus using LSI from both the Scikit-learn and Gensim libraries, however, when using the Gensim approach I was not able to display a list of documents to topic mapping.
Here is my work using Scikit-learn LSI where I successfully displayed document to topic mapping:
tfidf_transformer = TfidfTransformer()
transformed_vector = tfidf_transformer.fit_transform(transformed_vector)
NUM_TOPICS = 14
lsi_model = TruncatedSVD(n_components=NUM_TOPICS)
lsi= nmf_model.fit_transform(transformed_vector)
topic_to_doc_mapping = {}
topic_list = []
topic_names = []
for i in range(len(dbpedia_df.index)):
most_likely_topic = nmf[i].argmax()
if most_likely_topic not in topic_to_doc_mapping:
topic_to_doc_mapping[most_likely_topic] = []
topic_to_doc_mapping[most_likely_topic].append(i)
topic_list.append(most_likely_topic)
topic_names.append(topic_id_topic_mapping[most_likely_topic])
dbpedia_df['Most_Likely_Topic'] = topic_list
dbpedia_df['Most_Likely_Topic_Names'] = topic_names
print(topic_to_doc_mapping[0][:100])
topic_of_interest = 1
doc_ids = topic_to_doc_mapping[topic_of_interest][:4]
for doc_index in doc_ids:
print(X.iloc[doc_index])
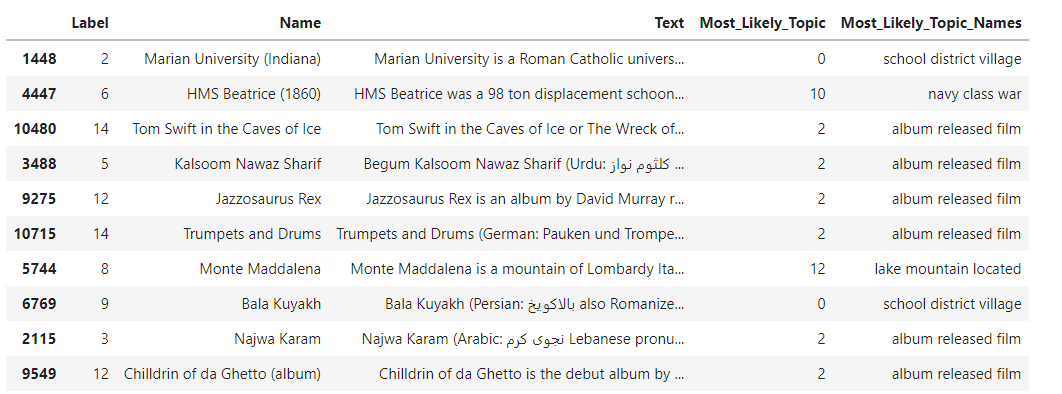
Using Gensim I was unable to proceed to display the document to topic mapping:
processed_list = []
stop_words = set(stopwords.words('english'))
lemmatizer = WordNetLemmatizer()
for doc in documents_list:
tokens = word_tokenize(doc.lower())
stopped_tokens = [token for token in tokens if token not in stop_words]
lemmatized_tokens = [lemmatizer.lemmatize(i, pos="n") for i in stopped_tokens]
processed_list.append(lemmatized_tokens)
term_dictionary = Dictionary(processed_list)
document_term_matrix = [term_dictionary.doc2bow(document) for document in processed_list]
NUM_TOPICS = 14
model = LsiModel(corpus=document_term_matrix, num_topics=NUM_TOPICS, id2word=term_dictionary)
lsi_topics = model.show_topics(num_topics=NUM_TOPICS, formatted=False)
lsi_topics
How can I display the document to topic mapping here?
CodePudding user response:
In order to get the representation of a document (represented as a bag-of-words) from a trained LsiModel as a vector of topics, you use Python dict-style bracket-accessing (model[bow]).
For example, to get the topics for the 1st item in your training data, you can use:
first_doc = document_term_matrix[0]
first_doc_lsi_topics = model[first_doc]
You can also supply a list of docs, as in training, to get the LSI topics for an entire batch at once. EG:
all_doc_lsi_topics = model[document_term_matrix]