I have a list of xlsx comments imported into R. It is a list of lists, where one of the elements present in each comment is a string representing the comment's location in Excel. I'd like to represent that as an [X,Y] numerical index, as it would be done in R.
list_of_comments
$ :List of 2
..$ location : chr "BA5"
..$ content : chr "some content"
$ :List of 2
you get the picture
I've tried doing it the hardcoded way by creating a data.frame of predefined cell names. Based on the matching content, the index would be returned. I soon realised I don't even know how to create that into the double character territory (e.g. AA2). And even if I did, I'd be left with a massive data.frame.
Is there a smart way of converting an Excel cell location into a row-column index?
CodePudding user response:
You can use the cellranger package which helps power readxl to help here, specifically the as.cell_addr() function:
library(cellranger)
library(dplyr)
list_of_comments <- list(list(location = "BG5", content = "abc"),
list(location = "AA2", content = "xyz"))
bind_rows(list_of_comments) %>%
mutate(as.cell_addr(location, strict = FALSE) %>%
unclass() %>%
as_tibble())
# A tibble: 2 x 4
location content row col
<chr> <chr> <int> <int>
1 BG5 abc 5 59
2 AA2 xyz 2 27
CodePudding user response:
In base R you can do:
excel <- c("F3", "BG5")
r_rows <- as.numeric(sub("^.*?(\\d )$", "\\1", excel))
r_cols <- sapply(strsplit(sub("^(. )\\d $", "\\1", excel), ""), function(x) {
val <- match(rev(x), LETTERS)
sum(val * 26^(seq_along(val) - 1))
})
data.frame(excel = excel, r_row = r_rows, r_col = r_cols)
#> excel r_row r_col
#> 1 F3 3 6
#> 2 BG5 5 59
Or if you want to just replace location within your list (using Ritchie's example data) you can do:
lapply(list_of_comments, function(l) {
excel <- l$location
r_row <- as.numeric(sub("^.*?(\\d )$", "\\1", excel))
r_col <- sapply(strsplit(sub("^(. )\\d $", "\\1", excel), ""), function(x) {
val <- match(rev(x), LETTERS)
sum(val * 26^(seq_along(val) - 1))
})
l$location <- c(row = r_row, col = r_col)
l
})
#> [[1]]
#> [[1]]$location
#> row col
#> 5 59
#>
#> [[1]]$comment
#> [1] "abc"
#>
#>
#> [[2]]
#> [[2]]$location
#> row col
#> 2 27
#>
#> [[2]]$comment
#> [1] "xyz"
Created on 2022-04-06 by the 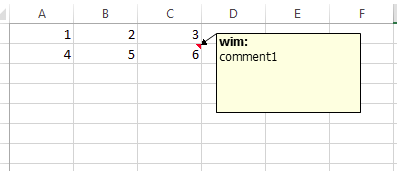
If you read the excel using tidyxl-pacgage, you can derive everyting directly from tne row/col columns
library(tidyxl)
cells <- xlsx_cells("./temp/xl_test.xlsx")
cells[!is.na(cells$comment), c(1:4,17)]
# A tibble: 1 x 5
# sheet address row col comment
# <chr> <chr> <int> <int> <chr>
# 1 Blad1 C2 2 3 "wim:\r\ncomment1"