I have to work with a PDF form created by a person unknown to me. Why did the program with which the form was created (Word PDF export?) split the term "Stunde" into "S", "t" and "unde" in line 6909 of the decoded PDF? There is no visual break between the three parts.
/TT1 1 Tf
11.04 0 0 11.04 59.16 476.1203 Tm
(Datum)Tj
/C2_1 1 Tf
<0003>Tj
/TT1 1 Tf
(der)Tj
0.424 -1.315 Td
(Tätigkeit)Tj
-0.0022 Tc 0 11.04 -11.04 0 261.24 437.7203 Tm
[(Ve)-4.6<7267fc74>-4.2(ungssat)-4.2(z)]TJ
/C2_1 1 Tf
0 Tc <0003>Tj
/TT1 1 Tf
-0.0021 Tc 0.935 -1.315 Td
[<2880>-6.1(/)-7.2(S)0.8(t)-4.1(unde)-4.5(\))]TJ % <<< the important line
0 Tc 11.04 0 0 11.04 340.92 468.8003 Tm
(Anlass/Art)Tj
/C2_1 1 Tf
resulting in
[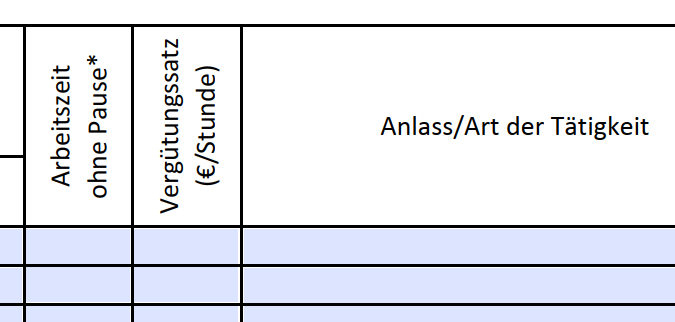 ]
]
To get the source code above, I decoded the PDF file as described here. I have no know-how concerning the PDF file format.
Background: I had to replace the word "Stunde", it drove me crazy to find the place where "Stunde" was written (in parts) within the source code, since no free PDF editor seems to be able to work with horizontal text without problems.
Academic Bonus questions: Is it possible to set the sum over a column as default value for a form field? (Modifiable; changed every time the column is changed.) Why was I able to replace "Stunde" with "Einsatz" without making the PDF file corrupt due to now irregular offsets?
CodePudding user response:
You don't see a visual break but the standard distance between "S", "t" and "unde" has been changed nonetheless. This is done by PDF writers that support e.g. kerning so that the word appear nicer. This is the reason why it is split that way.
CodePudding user response:
Why did the program with which the form was created (Word PDF export?) split the term "Stunde" into "S", "t" and "unde" in line 6909 of the decoded PDF?
As @gettalong mentioned in his answer, in your case this most likely has been done to apply kerning.
If you start looking into the outputs of some other PDF producers, you'll see that this export from Word actually is very unobtrusive in regard to splitting words:
- there are PDF producers that draw each character individually after explicitly setting the text matrix for it, and
- there also are PDF producers that have the width information for the characters of the used fonts set to zero and use the numbers in TJ instructions to forward the current text matrix between characters accordingly.
And this doesn't cover all the variants to be found, not by far...
Thus,
I had to replace the word "Stunde", it drove me crazy to find the place where "Stunde" was written (in parts) within the source code
in your case replacing actually was a fairly trivial task...
Is it possible to set the sum over a column as default value for a form field? (Modifiable; changed every time the column is changed.)
If all the column values in question are stored in form fields, you can use JavaScript to recalculate sums after form changes. To have it serve as "default" only, you can use some other (hidden) field for a flag whether the field has already been touched. Beware, though: JavaScript is not supported by all PDF viewers. Furthermore, the JavaScript object model for PDF is not specified in an independent (like ISO) specification but in an Adobe one which can make interpretation of the specification biased.
Why was I able to replace "Stunde" with "Einsatz" without making the PDF file corrupt due to now irregular offsets?
As we don't know how exactly you applied the changes, this obviously is hard to tell.
Most likely, though, you did corrupt the PDF and the PDF viewers you opened it in merely repair the corruption under the hood. There is a strong tendency in PDF viewers to do such under-the-hood repairs without informing the user; the result is that a large part of the PDFs in the wild actually being broken.