I have dataframe df with daily stock market for 10 years having columns Date, Open, Close.
I want to calculate the daily standard deviation of the close price. For this the mathematical formula is:
Step1: Calculate the daily interday change of the Close
Step2: Next, calculate the daily standard deviation of the daily interday change (calculated from Step1) for the last 1 year of data
Presently, I have figured out Step1 as per the code below. The column Interday_Close_change calculates the difference between each row and the value one day ago.
df = pd.DataFrame(data, columns=columns)
df['Close_float'] = df['Close'].astype(float)
df['Interday_Close_change'] = df['Close_float'].diff()
df.fillna('', inplace=True)
Questions:
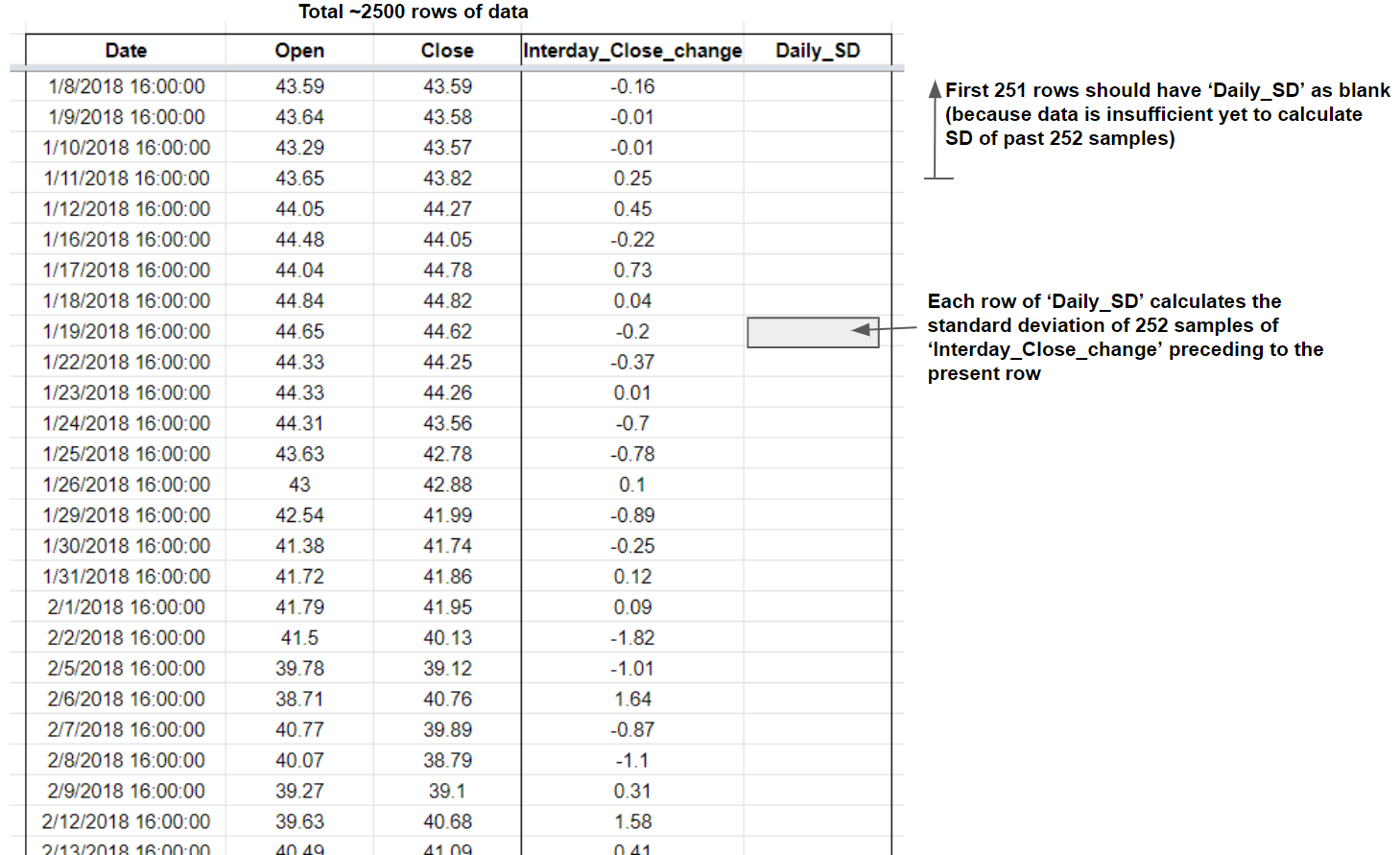
(a). How to I obtain a column Daily_SD which finds the standard deviation of the last 252 days (which is 1 year of trading days)? On Excel, we have the formula STDEV.S() to do this.
(b). The Daily_SD should begin on the 252th row of the data since that is when the data will have 252 datapoints to calculate from. How do I realize this?
CodePudding user response:
It looks like you are trying to calculate a rolling standard deviation, with the rolling window consisting of previous 252 rows.
Pandas has many .rolling() methods, including one for standard deviation:
df['Daily_SD'] = df['Interday_Close_change'].rolling(252).std().shift()
If there is less than 252 rows available from which to calculate the standard deviation, the result for the row will be a null value (NaN). Think about whether you really want to apply the .fillna('') method to fill null values, as you are doing. That will convert the entire column from a numeric (float) data type to object data type.
Without the .shift() method, the current row's value will be included in calculations. The .shift() method will shift all rolling standard deviation values down by 1 row, so the current row's result will be the standard deviation of the previous 252 rows, as you want.
with pandas version >= 1.2 you can use this instead:
df['Daily_SD'] = df['Interday_Close_change'].rolling(252, closed='left').std()
The closed=left parameter will exclude the last point in the window from calculations.