I have an excel file like this and I want the date field numbers to be converted to history like (2021.7.22) and replaced again using Python in the history field.
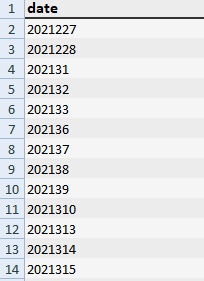
A friend sent me a code that almost answered me, but there is still a bug in the code.
This is the code I used
import pandas as pd
dfs = pd.read_excel('apal.xlsx', sheet_name=None)
output = {}
for ws, df in dfs.items():
if 'date' in df.columns:
df['date'] = df['date'].apply(lambda x: f'{str(x)[:4]}.'
f'{str(x)[4:6 if len(str(x)) > 7 else 5]}.{str(x)[-2:]}')
output[ws] = df
writer = pd.ExcelWriter('TestOutput.xlsx')
for ws, df in output.items():
df.to_excel(writer, index=None, sheet_name=ws)
writer.save()
writer.close()
But the output has a bug and in some data the numbers of months are rewritten next to the numbers of the day.
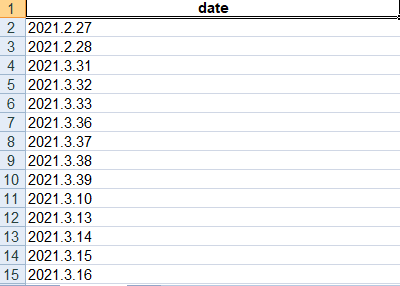
Like 2021.3.32, in fact, such a number did not exist in my original data at all
CodePudding user response:
You need to solve the ambiguity for dates like 2021111. In a first time, you can use pd.to_datetime:
df['date2'] = pd.to_datetime(df['date'], format='%Y%m%d').dt.strftime('%Y.%-m.%-d')
print(df)
# Output
date date2
0 2021227 2021.2.27
1 2021228 2021.2.28
2 202131 2021.3.1
3 202132 2021.3.2
4 202133 2021.3.3
5 202136 2021.3.6
6 202137 2021.3.7
7 202138 2021.3.8
8 202139 2021.3.9
9 2021310 2021.3.10
10 2021313 2021.3.13
11 2021314 2021.3.14
12 2021315 2021.3.15
13 2021111 2021.11.1 # <- default interpretation of 2021111