So I have a massive list of numbers where all lines contain the same format.
#976B4B|B|0|0
#970000|B|0|1
#974B00|B|0|2
#979700|B|0|3
#4B9700|B|0|4
#009700|B|0|5
#00974B|B|0|6
#009797|B|0|7
#004B97|B|0|8
#000097|B|0|9
#4B0097|B|0|10
#970097|B|0|11
#97004B|B|0|12
#970000|B|0|13
#974B00|B|0|14
#979700|B|0|15
#4B9700|B|0|16
#009700|B|0|17
#00974B|B|0|18
#009797|B|0|19
#004B97|B|0|20
#000097|B|0|21
#4B0097|B|0|22
#970097|B|0|23
#97004B|B|0|24
#2C2C2C|B|0|25
#979797|B|0|26
#676767|B|0|27
#97694A|B|0|28
#020202|B|0|29
#6894B4|B|0|30
#976B4B|B|0|31
#808080|B|1|0
#800000|B|1|1
#803F00|B|1|2
#808000|B|1|3
What I am trying to do is remove all duplicate lines that contain the same hex codes, regardless of the text after it.
Example, in the first line #976B4B|B|0|0 the hex #976B4B shows up in line 32 as #976B4B|B|0|31. I want all lines EXCEPT the first occurrence to be removed.
I have been attempting to use regex to solve this, and found ^(.*)(\r?\n\1) $ $1 can remove duplicate lines but obviously not what I need. Looking for some guidance and maybe a possibility to learn from this.
CodePudding user response:
You can use the following regex replacement, make sure you click Replace All as many times as necessary, until no match is found:
Find What: ^((#[[:xdigit:]] )\|.*(?:\R. )*?)\R\2\|.*
Replace With: $1
See the 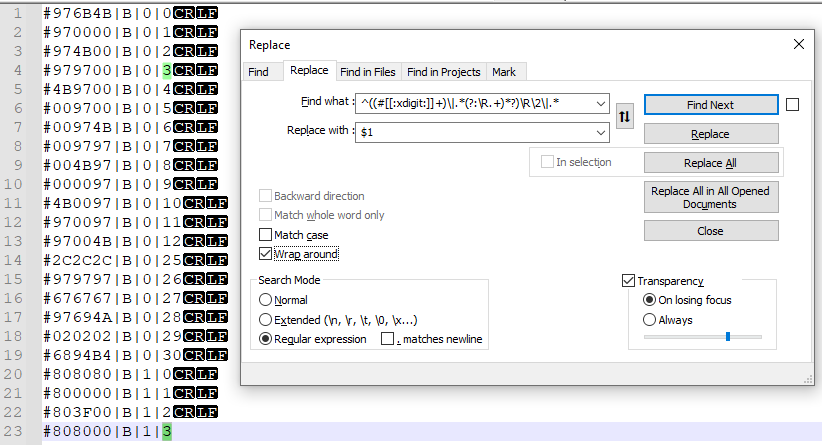
Details:
^- start of a line((#[[:xdigit:]] )\|.*(?:\R. )*?)- Group 1 ($1, it will be kept):(#[[:xdigit:]] )- Group 2:#and one or more hex chars\|- a|char.*- the rest of the line(?:\R. )*?- any zero or more non-empty lines (if they can be empty, replace.with.*)
\R\2\|.*- a line break, Group 2 value,|and the rest of the line.