I am currently experimenting with web scraping my own Stack Overflow 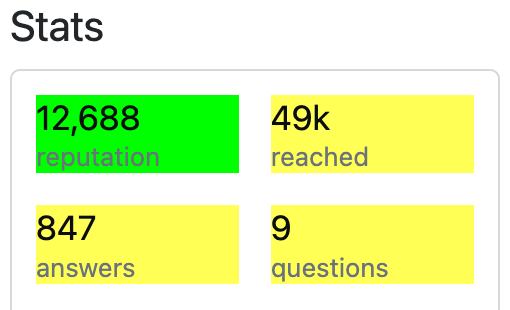
This gives me the following CSS tags: .md\:fl-auto , .fc-dark. The .fc-dark tag is for the numbers and .md\:fl-auto for the headers (reputation, reached, etc.). Extracting the numbers works, but extracting the headers, I get the following error: Error: '\:' is an unrecognized escape in character string starting "".md\:". Is it possible to extract this CSS tag and save both outputs in a dataframe? Here is a reproducible example:
library(rvest)
library(dplyr)
link <- "https://stackoverflow.com/users/14282714/quinten"
profile <- read_html(link)
numbers <- profile %>% html_nodes(".fc-dark") %>% html_text()
numbers
[1] "12,688" "49k" "847" "9"
headers <- profile %>% html_nodes(".md\:fl-auto") %>% html_text()
Error: '\:' is an unrecognized escape in character string starting "".md\:"
I am open to better options for web scraping my StackOverflow profile!
CodePudding user response:
library(rvest)
library(dplyr)
library(stringr)
profile %>% html_nodes(".md\\:fl-auto") %>% html_text() %>%
stringr::str_squish() %>%
as_tibble() %>%
tidyr::separate(value, into = c("number", "header"), sep = "\\s") %>%
mutate(number = stringr::str_remove(number, "\\,") %>%
sub("k", "000", ., fixed = TRUE))
Output:
# A tibble: 4 x 2
number header
<dbl> <chr>
1 12688 reputation
2 49000 reached
3 847 answers
4 10 questions