I have a SQL Server 2016 database representing patients (pID), with visits (vID) to a healthcare facility. When patients move facilities, new visits are created.
I would like to piece together visits where the admit/discharge dates (represented by example ints vdStart and vdEnd) are close to one another (fuzzy joining), and display these as extra columns, thus having 1 row representing a patients healthcare journey. Future visits that aren't close to previous visits are separate journeys.
Here's some sample data:
CREATE TABLE t
(
[pID] varchar(7),
[vID] int,
[vdStart] int,
[vdEnd] int
);
INSERT INTO t ([pID], [vID], [vdStart], [vdEnd])
VALUES
('Jenkins', 1, 100, 102),
('Jenkins', 3, 102, 110),
('Jenkins', 7, 111, 130),
('Barnaby', 2, 90, 114),
('Barnaby', 5, 114, 140),
('Barnaby', 9, 153, 158),
('Forster', 4, 100, 130),
('Smith', 6, 120, 131),
('Smith', 8, 140, 160),
('Everett', 10, 158, 165),
('Everett', 12, 165, 175),
('Everett', 15, 186, 190),
('Everett', 17, 190, 195),
('Everett', 18, 195, 199),
('Everett', 19, 199, 210)
;
Here's an example of what I want:
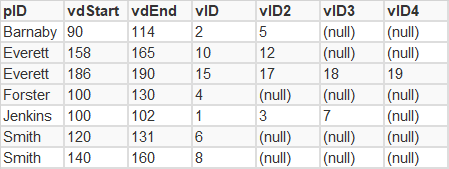
Visits that all correspond to the same "healthcare journey" are joined. New row for each.
I wasn't able to get the PIVOT function to do what I wanted based on a fuzzy joining logic (which is supposed to represent datetimes)). My approach was using LEAD, however this quickly becomes silly when trying to connect beyond 2 visits, and it was showing incorrect values with gaps in between, which I don't want.
SELECT
pID,
vdStart,
vdEnd,
vID,
(
CASE WHEN ((
LEAD (vdStart, 1) OVER (PARTITION BY pID ORDER BY vdStart ASC)
) - vdEnd < 2) THEN (
LEAD (vID, 1) OVER (PARTITION BY pID ORDER BY vdStart ASC)
) ELSE NULL END
) AS vID2,
(
CASE WHEN ((
LEAD (vdStart, 2) OVER (PARTITION BY pID ORDER BY vdStart ASC)
) - (
LEAD (vdEnd, 1) OVER (PARTITION BY pID ORDER BY vdStart ASC)
) < 2) THEN (
LEAD (vID, 2) OVER (PARTITION BY pID ORDER BY vdStart ASC)
) ELSE NULL END
) AS vID3,
(
CASE WHEN ((
LEAD (vdStart, 3) OVER (PARTITION BY pID ORDER BY vdStart ASC)
) - (
LEAD (vdEnd, 2) OVER (PARTITION BY pID ORDER BY vdStart ASC)
) < 2) THEN (
LEAD (vID, 3) OVER (PARTITION BY pID ORDER BY vdStart ASC)
) ELSE NULL END
) AS vID4
FROM t
;
I'm unsure how else to approach this based on the fuzzy pivot logic I'm after. This only needs to be run occasionally, and should run in less than 10 minutes.
CodePudding user response:
This is a classic gaps-and-islands problem.
One solution uses a conditional count
- Get the each row's previous using
LAG - Use a conditional count to number the groups of rows.
- Use
ROW_NUMBERto number each row within the group - Group up and pivot by
pIDand group ID.
WITH cte1 AS (
SELECT *,
PrevEnd = LAG(t.vdEnd) OVER (PARTITION BY t.pID ORDER BY t.vdStart)
FROM t
),
cte2 AS (
SELECT *,
GroupId = COUNT(CASE WHEN cte1.PrevEnd >= cte1.vdStart - 1 THEN NULL ELSE 1 END)
OVER (PARTITION BY cte1.pID ORDER BY cte1.vdStart ROWS UNBOUNDED PRECEDING)
FROM cte1
),
Numbered AS (
SELECT *,
rn = ROW_NUMBER() OVER (PARTITION BY cte2.pID, cte2.GroupID ORDER BY cte2.vdStart)
FROM cte2
)
SELECT
n.pID,
vdStart = MIN(n.vdStart),
vdEnd = MIN(n.vdEnd),
vID = MIN(CASE WHEN n.rn = 1 THEN n.vID END),
vID1 = MIN(CASE WHEN n.rn = 2 THEN n.vID END),
vID2 = MIN(CASE WHEN n.rn = 3 THEN n.vID END),
vID3 = MIN(CASE WHEN n.rn = 4 THEN n.vID END)
FROM Numbered n
GROUP BY
n.pID,
n.GroupID
ORDER BY
n.pID,
n.GroupID;
Another option you can use is a recursive algorithm
- Get all rows which are starting rows (no previous rows in the sequence for this
pID) - Recursively get the next row in the sequence, keeping track of the first row's
vdStart. - Number the sequence results.
- Group up and pivot by
pIDand sequence number.
WITH cte AS (
SELECT pID, vID, vdStart, vdEnd, GroupID = vdStart
FROM t
WHERE NOT EXISTS (SELECT 1
FROM t Other
WHERE Other.pID = t.pID
AND t.vdStart BETWEEN Other.vdEnd AND Other.vdEnd 1)
UNION ALL
SELECT t.pID, t.vID, t.vdStart, t.vdEnd, cte.GroupID
FROM cte
JOIN t ON t.pID = cte.pID AND t.vdStart BETWEEN cte.vdEnd AND cte.vdEnd 1
),
Numbered AS (
SELECT *,
rn = ROW_NUMBER() OVER (PARTITION BY cte.pID, cte.GroupID ORDER BY cte.vdStart)
FROM cte
)
SELECT
n.pID,
vdStart = MIN(n.vdStart),
vdEnd = MIN(n.vdEnd),
vID = MIN(CASE WHEN n.rn = 1 THEN n.vID END),
vID1 = MIN(CASE WHEN n.rn = 2 THEN n.vID END),
vID2 = MIN(CASE WHEN n.rn = 3 THEN n.vID END),
vID3 = MIN(CASE WHEN n.rn = 4 THEN n.vID END)
FROM Numbered n
GROUP BY
n.pID,
n.GroupID
ORDER BY
n.pID,
n.GroupID;