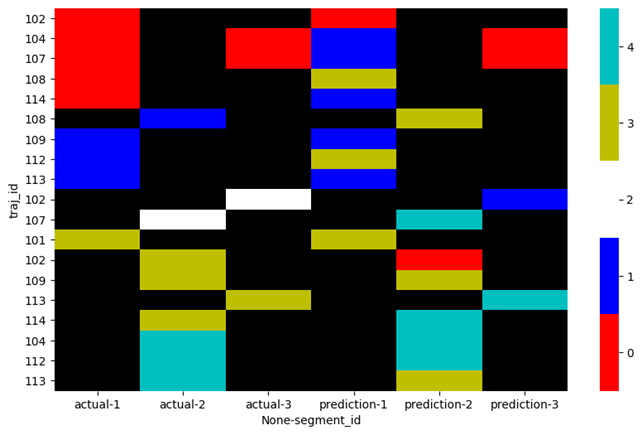
My dataframe consists of trajectories split into segments. Other columns represent the actual class of a segment, and predicted label for that same segment.
Here I give an example of how it looks like:
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.colors as mcolors
import seaborn as sns
data = {'traj_id': [101,102,102,102,102,102,102,102,104,104,104,104,104,104,104,107,107,107,
107,107,107,107,107,107,108,108,108,108,108,108,108,109,109,109,109,109,
109,112,112,112,112,112,113,113,113,113,114,114,114,114],
'segment_id': [1,1,1,1,2,2,3,3,1,1,2,2,2,3,3,1,1,2,2,2,2,3,3,3,1,1,1,2,2,2,2,1,1,1,2,2,2,
1,1,2,2,2,1,2,2,3,1,2,2,2],
'actual': [3,0,0,1,3,3,2,2,0,0,4,4,2,0,0,0,0,2,2,2,3,0,0,2,0,0,1,1,1,1,0,1,2,1,3,3,3,1,1,
4,4,2,1,4,4,3,0,3,3,2],
'prediction' :[3,0,1,0,0,3,1,2,1,3,4,2,4,0,3,1,0,4,2,3,0,0,4,2,3,0,0,3,1,1,0,1,2,1,3,3,1,
3,1,4,1,4,1,3,1,4,1,4,1,3] }
df = pd.DataFrame(data)
df.head()
traj_id segment_id actual prediction
0 101 1 3 3
1 102 1 0 0
2 102 1 0 1
3 102 1 1 0
4 102 2 3 0
I am doing a plot of the trajectories on x-axis and segments on y-axis. So I write a custom function, that takes in the df and segment's true class represented by actual column. This function sorts the segments so that all segments labelled 0 from all trajectories are plotted, following by all segments labelled 1 from all trajectories, and so on. I give the function's code as below:
def plot_spectral(df, column_name):
plt.style.use(['default'])
cmap = mcolors.ListedColormap(['r', 'b', 'w', 'y', 'c'])
cmap.set_bad('k')
plot_data = df.drop_duplicates(['traj_id', 'segment_id'])
plot_data = pd.concat([plot_data[plot_data[column_name].eq(p)]
.pivot_table(index='traj_id', columns='segment_id', values=column_name)
for p in sorted(plot_data[column_name].unique())]).sort_index(axis=1)
fig, ax = plt.subplots(figsize=(10,6))
sns.heatmap(plot_data, vmin=-0.5, vmax=4.5,cmap=cmap, annot=False)
colorbar = ax.collections[0].colorbar
colorbar.set_ticks([0, 1., 2., 3, 4])
plt.show()
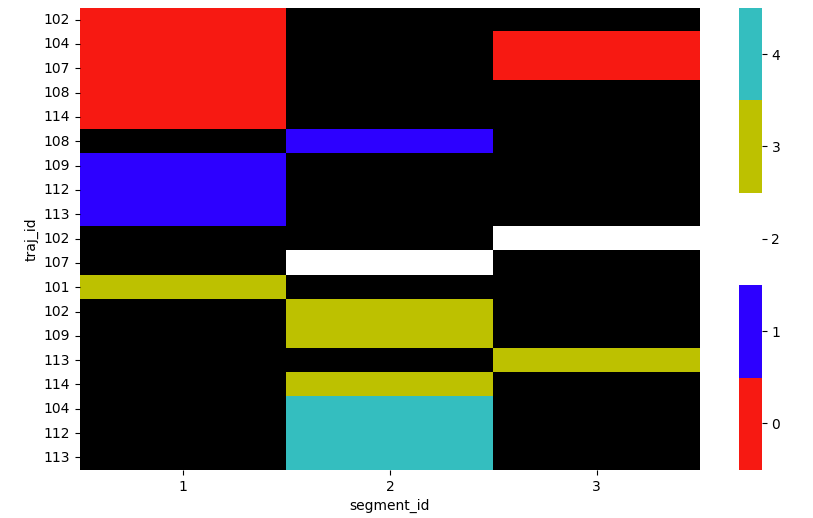
Taking the example df above, I plot the true class (column actual) like so:
plot_spectral(df, 'actual')
Output:
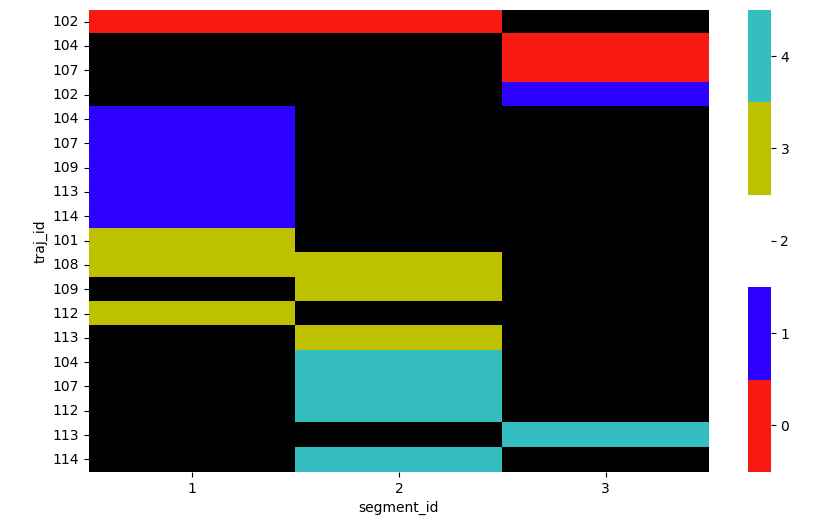
I can also plot the prediction in similar way:
plot_spectral(df, 'prediction')
Output:
The Question
The prediction plot (second) is fine, but not easy for comparison against the actual labels (first plot), since it is also sorted according to predicted classes 0 then 1, etc...
So needed a way to modify my function, so that the ordering for true class (actual) is maintained throughout. For the prediction plot, it is not required to have 0s first before 1s. In the case of the prediction plot, whatever class is predicted for the true class order should be plotted as it is.
This will allow me easily figure out, for example:
segment_id = 1oftraj_id: 102, 104, 107, 108, 114that are actually0swhat is each of these predicted as (colour code)?segment_id = 3oftraj_id: 104, 107that are actually0s, what is each predicted as?segment_id = 2oftraj_id: 108is actually a1, what is it predicted as?segment_id = 1oftraj_id: 109, 112, 113are actually1s, but what is each of these predicted as?- and so on...
Only maintaining the ordering of first plot (actual) in the second plot (prediction) would help easily answer this.
How then do I modify my "hard-coded" function to achieve this aim?
CodePudding user response:
Put both actual and prediction values in the pivot table and then plot either column group or both of them side by side. For this it's best to split data processing and plotting into two separate functions.
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.colors as mcolors
import seaborn as sns
data = {'traj_id': [101,102,102,102,102,102,102,102,104,104,104,104,104,104,104,107,107,107,
107,107,107,107,107,107,108,108,108,108,108,108,108,109,109,109,109,109,
109,112,112,112,112,112,113,113,113,113,114,114,114,114],
'segment_id': [1,1,1,1,2,2,3,3,1,1,2,2,2,3,3,1,1,2,2,2,2,3,3,3,1,1,1,2,2,2,2,1,1,1,2,2,2,
1,1,2,2,2,1,2,2,3,1,2,2,2],
'actual': [3,0,0,1,3,3,2,2,0,0,4,4,2,0,0,0,0,2,2,2,3,0,0,2,0,0,1,1,1,1,0,1,2,1,3,3,3,1,1,
4,4,2,1,4,4,3,0,3,3,2],
'prediction' :[3,0,1,0,0,3,1,2,1,3,4,2,4,0,3,1,0,4,2,3,0,0,4,2,3,0,0,3,1,1,0,1,2,1,3,3,1,
3,1,4,1,4,1,3,1,4,1,4,1,3] }
df = pd.DataFrame(data)
def make_plot_data(df):
plot_data = df.drop_duplicates(['traj_id', 'segment_id'])
return pd.concat([plot_data[plot_data['actual'].eq(p)]
.pivot_table(index='traj_id', columns='segment_id', values=['actual', 'prediction'])
for p in sorted(plot_data['actual'].unique())]).sort_index(axis=1)
def plot_spectral(plot_data, column_name=None):
plt.style.use(['default'])
cmap = mcolors.ListedColormap(['r', 'b', 'w', 'y', 'c'])
cmap.set_bad('k')
fig, ax = plt.subplots(figsize=(10,6))
if column_name:
ax.set_title(column_name)
plot_data = plot_data[column_name]
sns.heatmap(plot_data, vmin=-0.5, vmax=4.5,cmap=cmap, annot=False)
colorbar = ax.collections[0].colorbar
colorbar.set_ticks(range(5))
plt.show()
plot_data = make_plot_data(df)
The plot the actual values plot_spectral(plot_data, 'actual'):
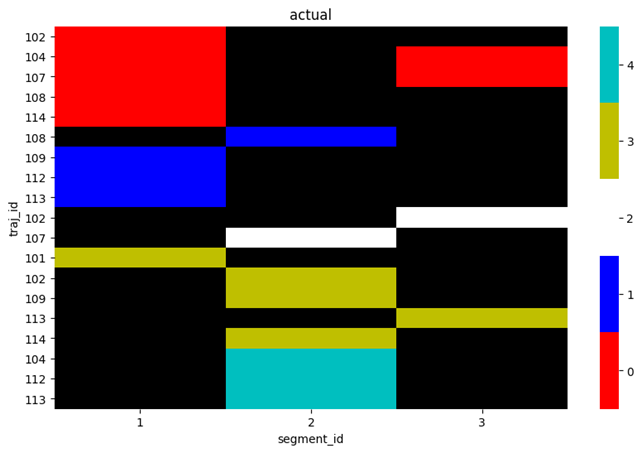
or plot the predicted values plot_spectral(plot_data, 'prediction'):
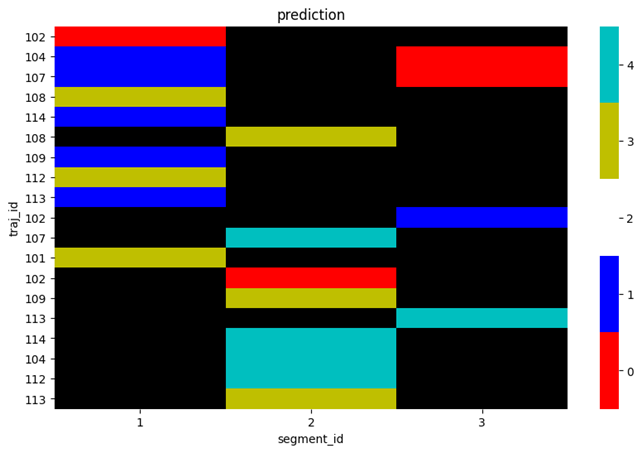
or plot both of them side by side plot_spectral(plot_data):