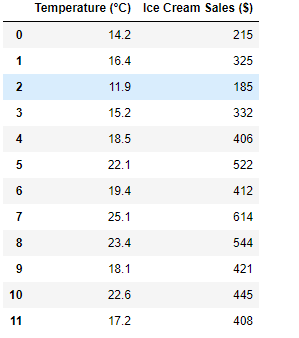
Dataset:
df = pd.read_excel('sales.xlsx')
x = df['Temperature (°C)']
y = df['Ice Cream Sales ($)']
df
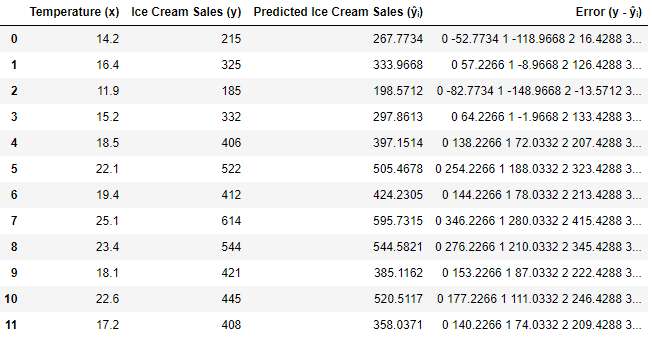
I made another table for regression squared error and used for loop to perform the y - ŷᵢ formula using this code:
sse = pd.DataFrame()
sse['Temperature (x)'] = x
sse['Ice Cream Sales (y)'] = y
sse['Predicted Ice Cream Sales (ŷᵢ)'] = [i for i in re]
sse['Error (y - ŷᵢ)'] = [i - round(re, 4) for i in y]
sse
And the output looks like this:
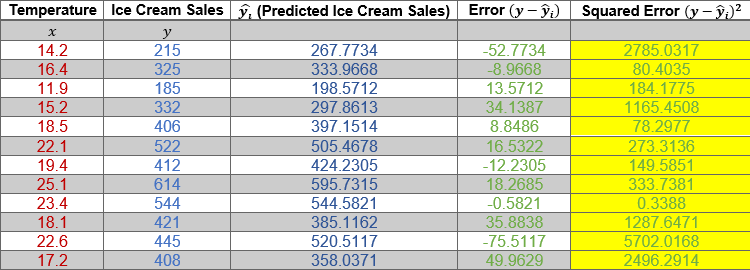
Desired output should look like this:
The problem is when using the for loop, it reads every value of y as supposed to just the corresponding value in each row or index.
Btw here's how I did the re(regression equation) as the problem might be here as to why the for loop included every y value
re = [round(round(slope, 4) * i round(itc, 4), 4) for i in x]
re = pd.Series(re)
re

My regression equation for this dataset is:

CodePudding user response:
Use vectorization, and avoid creating unnecessary intermediate objects (like [i for i in re]).
sse = pd.DataFrame(
{
'Temperature (x)': x,
'Ice Cream Sales (y)': y,
'Predicted Ice Cream Sales (ŷᵢ)': re,
'Error (y - ŷᵢ)': y - re.round(4),
}
)
CodePudding user response:
Did you try something like this:
sse['Predicted Ice Cream Sales (ŷᵢ)'] = pd.Series([round(round(slope, 4) * i round(itc, 4), 4) for i in x])
sse['Error (y - ŷᵢ)'] = y - round(sse['Predicted Ice Cream Sales (ŷᵢ)'], 4)
Result looks like this:
