I need help with ideas for parsing this text.
I want do it the most automatic way possible.
This is the text
text <- "JOHN DEERE: PMWF2126 NEW HOLLAND: 441702A1 HIFI: WE 2126 CUMMINS: 4907485"
I need this result:
| a | b |
|---|---|
| JOHN DEERE | PMWF2126 |
| NEW HOLLAND | 441702A1 |
| HIFI | WE 2126 |
| CUMMINS | 4907485 |
This is an example, there is a different marks an item id
I try:
str_split(text, " ")
[[1]]
[1] "JOHN" "DEERE:" "PMWF2126" "NEW" "HOLLAND:" "441702A1" "HIFI:" "WE" "2126"
[10] "CUMMINS:" "4907485" "CUMMINS:" "3680433" "CUMMINS:" "3680315" "CUMMINS:" "3100310"
Thanks!
CodePudding user response:
Thje sulution assumes (as in your sample data), that the second value always ends with a number, and the first column does not.
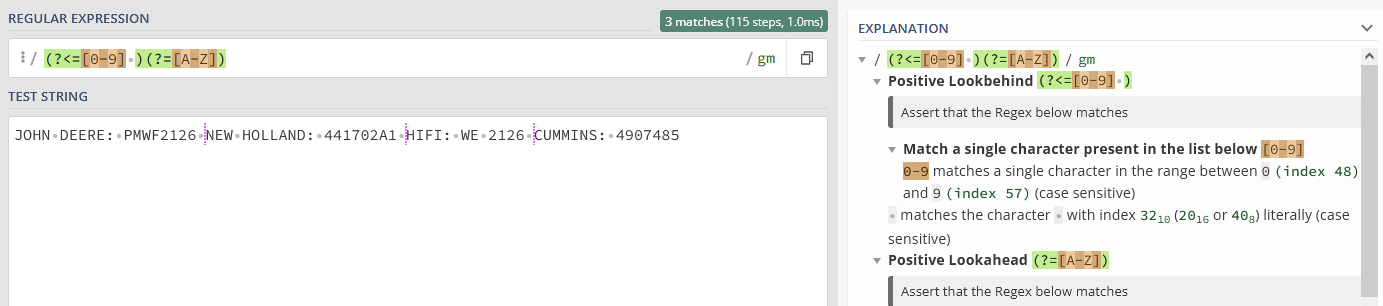
If this s not the case, you'll have to adapt the regex-part (?<=[0-9] )(?=[A-Z]), so that the splitting point lies between the two round-bracketed parts.
text <- "JOHN DEERE: PMWF2126 NEW HOLLAND: 441702A1 HIFI: WE 2126 CUMMINS: 4907485"
lapply(
strsplit(
unlist(strsplit(text, "(?<=[0-9] )(?=[A-Z])", perl = TRUE)),
":"), trimws)
[[1]]
[1] "JOHN DEERE" "PMWF2126"
[[2]]
[1] "NEW HOLLAND" "441702A1"
[[3]]
[1] "HIFI" "WE 2126"
[[4]]
[1] "CUMMINS" "4907485"
the key part is the strsplit(text, "(?<=[0-9] )(?=[A-Z])", perl = TRUE) part.
This looks for occurences where, after a numeric value followed by a space ?<=[0-9] , there is a new part, starting with a capital ?=[A-Z].
These positions are the used as splitting points
CodePudding user response:
Since the second field always ends in a digit and the first field does not, replace a digit followed by space with that digit and a newline and then use read.table with a colon separator.
text |>
gsub("(\\d) ", "\\1\n", x = _) |>
read.table(text = _, sep = ":", strip.white = TRUE)
giving
V1 V2
1 JOHN DEERE PMWF2126
2 NEW HOLLAND 441702A1
3 HIFI WE 2126
4 CUMMINS 4907485
If in your data the second field can have a digit but the first cannot and the digit is not necessarily at the end of the last word in field two but could be anywhere in the last word in field 2 then we can use this variation which gives the same result here. gsubfn is like gsub except the 2nd argument can be a function instead of a replacement string and it takes the capture group as input and replaces the entire match with the output of the function. The function can be expressed in formula notation as is done here.
library(gsubfn)
text |>
gsubfn("\\w ", ~ if (grepl("[0-9]", x)) paste(x, "\n") else x, x = _) |>
read.table(text = _, sep = ":", strip.white = TRUE)