In R,
With
a) list containing regions (Northeast, South, North Central, West) that each state belongs to
regions <- list(
west = c("WA", "OR", "CA", "NV", "AZ", "ID", "MT", "WY",
"CO", "NM", "UT"),
south = c("TX", "OK", "AR", "LA", "MS", "AL", "TN", "KY",
"GA", "FL", "SC", "NC", "VA", "WV"),
midwest = c("KS", "NE", "SD", "ND", "MN", "MO", "IA", "IL",
"IN", "MI", "WI", "OH"),
northeast = c("ME", "NH", "NY", "MA", "RI", "VT", "PA",
"NJ", "CT", "DE", "MD", "DC")
)
And b) a data.frame with States and Deaths
#A tibble:
state Deaths
<chr> <int>
1 AL 29549
2 AK 741
3 AR 50127
4 NJ 15142
5 CA 175213
6 IA 1647
...
I want to create a new variable, matching each state to it's region and summarizing Deaths. What's the best approach to do this?
CodePudding user response:
We may stack the list to a two column data.frame and do a join
library(dplyr)
stack(regions) %>%
left_join(df1, ., by = c("state" = "values")) %>%
rename(region = 'ind')
-output
state Deaths region
1 AL 29549 south
2 AK 741 <NA>
3 AR 50127 south
4 NJ 15142 northeast
5 CA 175213 west
6 IA 1647 midwest
If the df1 have duplicate rows, we may do a group by summarise
stack(regions) %>%
left_join(df1, ., by = c("state" = "values")) %>%
group_by(state, region = 'ind') %>%
summarise(Deaths = sum(Deaths, na.rm = TRUE), .groups = 'drop')
data
df1 <- structure(list(state = c("AL", "AK", "AR", "NJ", "CA", "IA"),
Deaths = c(29549L, 741L, 50127L, 15142L, 175213L, 1647L)),
class = "data.frame", row.names = c("1",
"2", "3", "4", "5", "6"))
CodePudding user response:
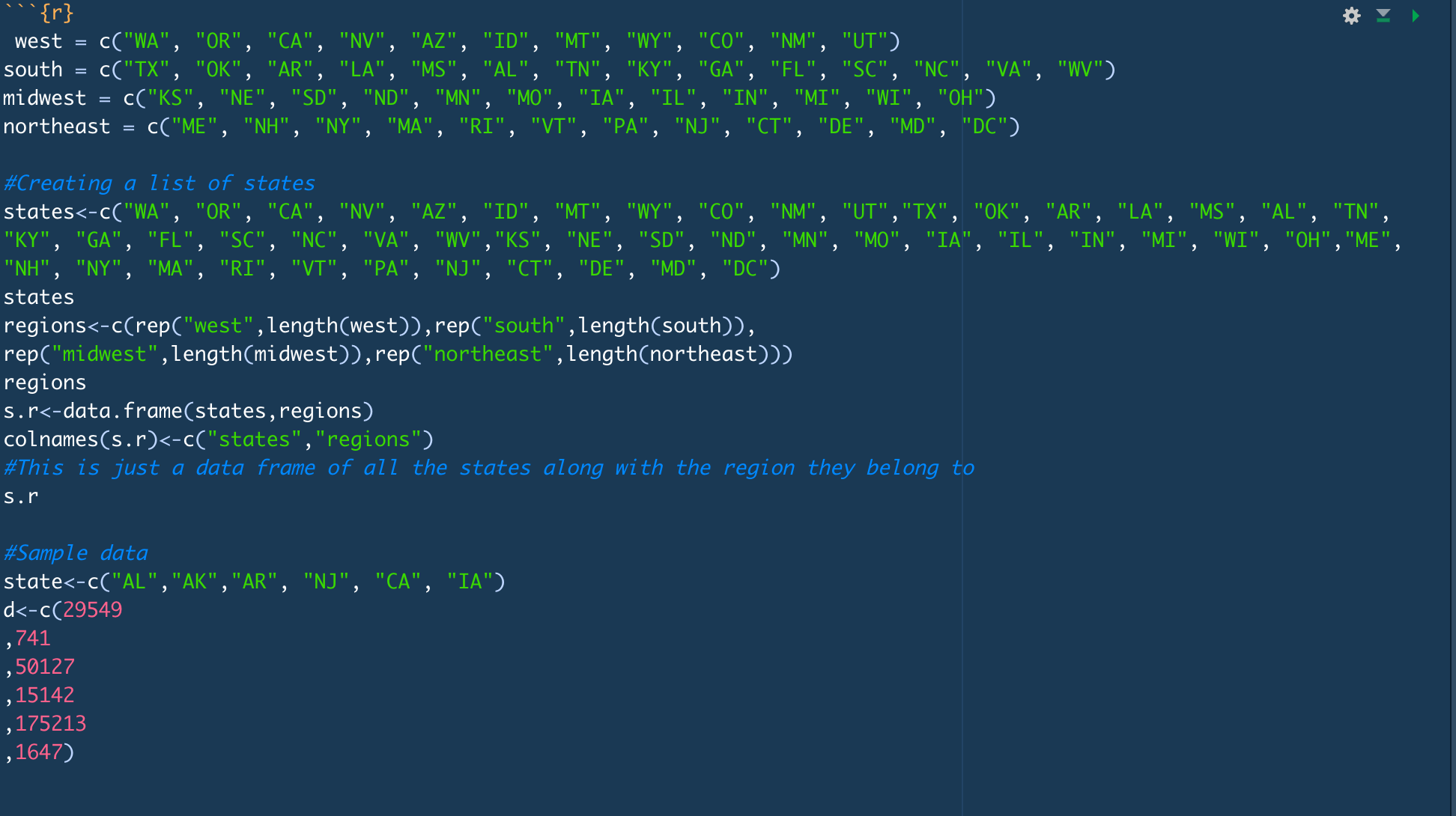 What I did here was just create the list into a data frame with one column denoting the region and the other a list of states
What I did here was just create the list into a data frame with one column denoting the region and the other a list of states
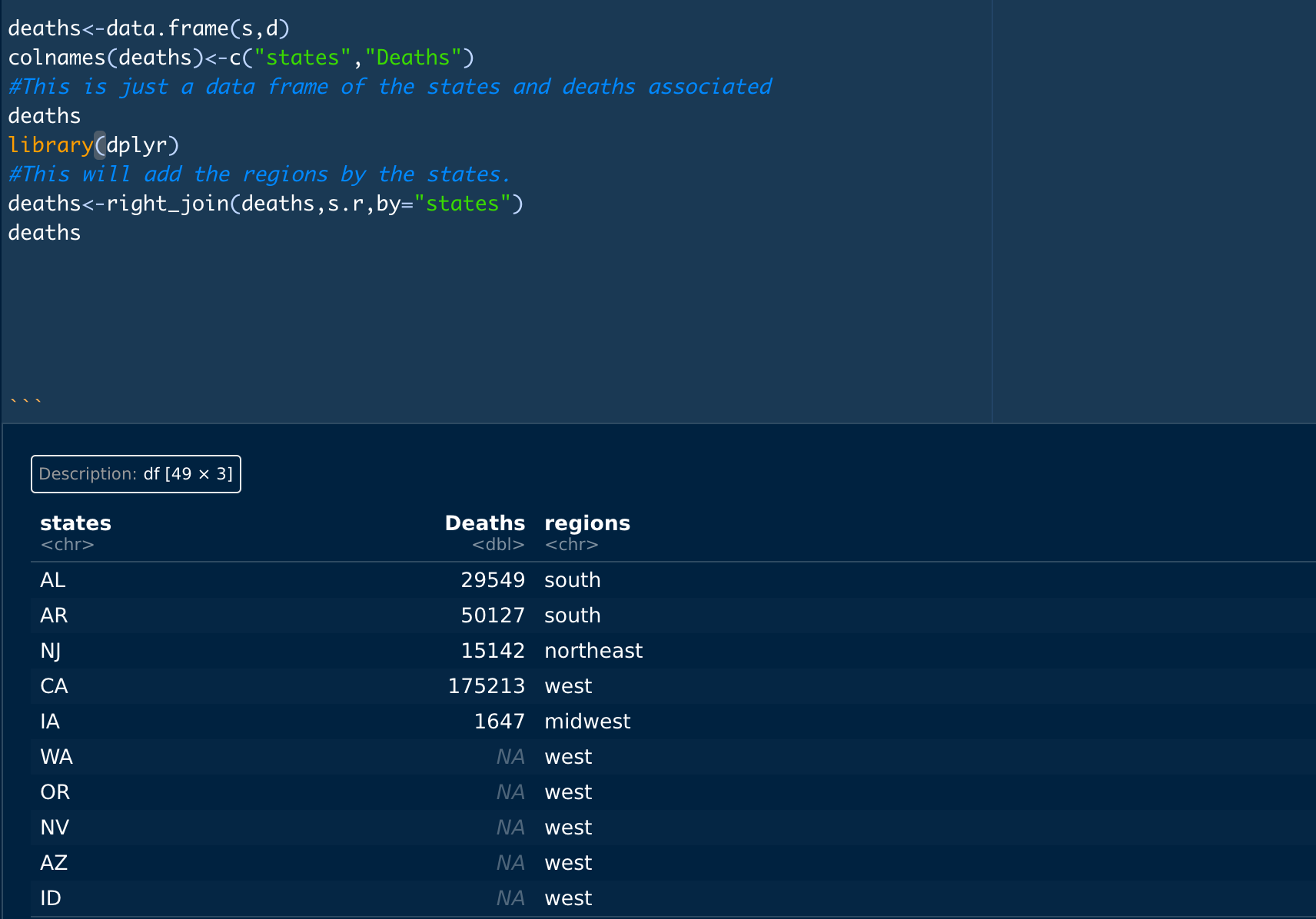
Here I used a dplyr function "right_join" which will "line up" the different rows and columns based on specific values. So here we want to line up the corresponding region based on states.