how to write a regex expression extract hadoop mr counter data from stderr logfile,
how to findall \t line with \t\t line pair data, I wrote a regular (re.findall(r'(\t[a-zA-Z\s] )\n(.*?)\n\t\w ', text, re.S|re.M)) but it is not correct
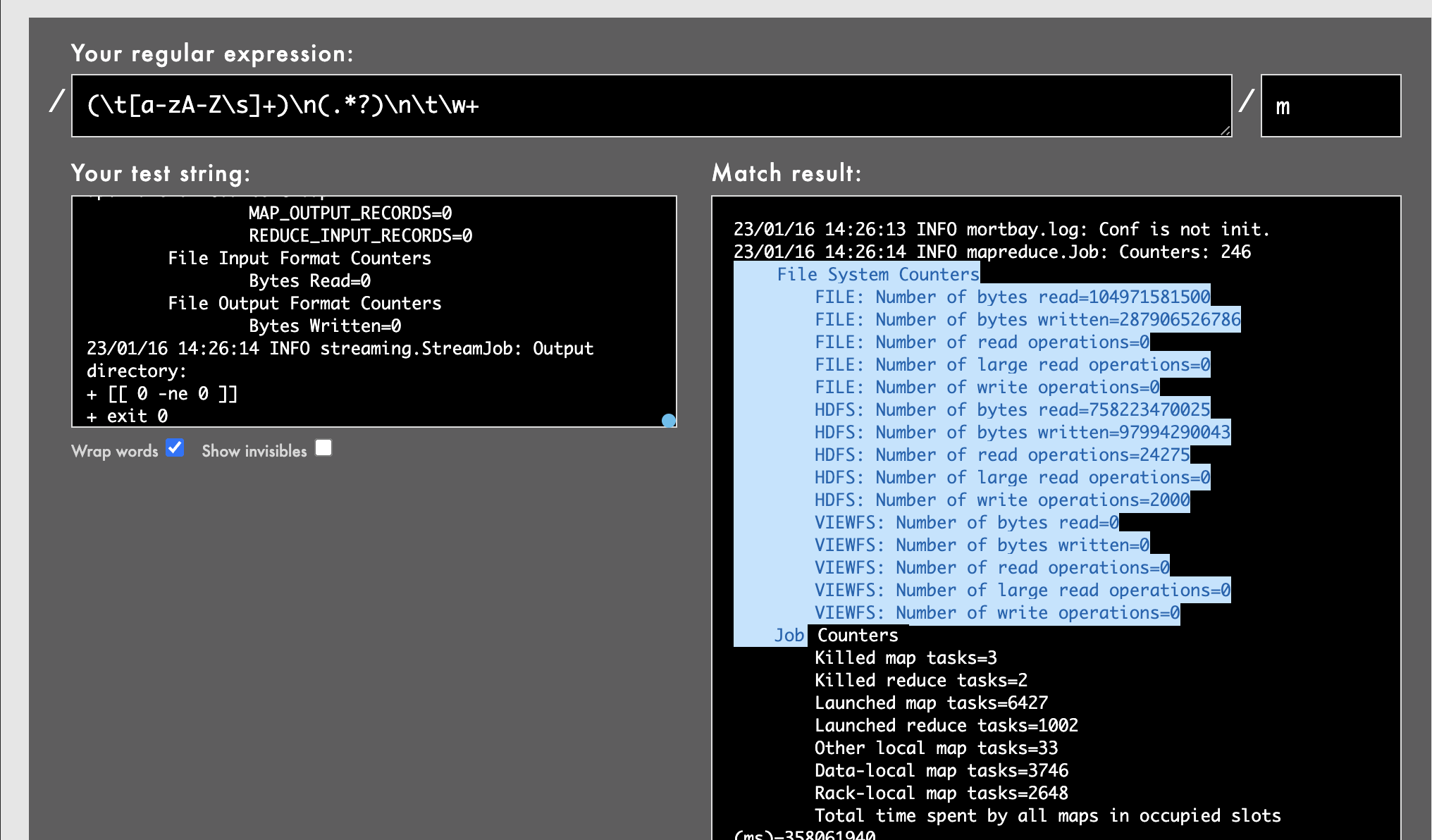
this is the stderr log sample
23/01/16 14:26:13 INFO mortbay.log: Conf is not init.
23/01/16 14:26:14 INFO mapreduce.Job: Counters: 246
File System Counters
FILE: Number of bytes read=104971581500
FILE: Number of bytes written=287906526786
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=758223470025
HDFS: Number of bytes written=97994290043
HDFS: Number of read operations=24275
HDFS: Number of large read operations=0
HDFS: Number of write operations=2000
VIEWFS: Number of bytes read=0
VIEWFS: Number of bytes written=0
VIEWFS: Number of read operations=0
VIEWFS: Number of large read operations=0
VIEWFS: Number of write operations=0
Job Counters
Killed map tasks=3
Killed reduce tasks=2
Launched map tasks=6427
Launched reduce tasks=1002
Other local map tasks=33
Data-local map tasks=3746
Rack-local map tasks=2648
Total time spent by all maps in occupied slots (ms)=358061940
Total time spent by all reduces in occupied slots (ms)=858021936
Total time spent by all map tasks (ms)=119353980
Total time spent by all reduce tasks (ms)=107252742
Total vcore-milliseconds taken by all map tasks=119353980
Total vcore-milliseconds taken by all reduce tasks=107252742
Total megabyte-milliseconds taken by all map tasks=305546188800
Total megabyte-milliseconds taken by all reduce tasks=878614462464
Map-Reduce Framework
Map input records=30951997
Map output records=30951997
Shuffled Maps =6425000
Failed Shuffles=46
Merged Map outputs=6425000
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=0
23/01/16 14:26:14 INFO streaming.StreamJob: Output directory:
[[ 0 -ne 0 ]]
exit 0
CodePudding user response:
You could match a lines starting with a single tab, followed by 1 or more lines that start with 2 tabs and a non whitespace character:
You can also only use re.M
^\t[a-zA-Z].*(?:\n\t\t\S.*)
See a regex101 demo.
If the rest of the line can also be empty after matching 2 tabs, you can just only .*
^\t[a-zA-Z].*(?:\n\t\t.*)
See another regex101 demo.